Databricks数据洞察存储如何助力企业挖掘数据价值?

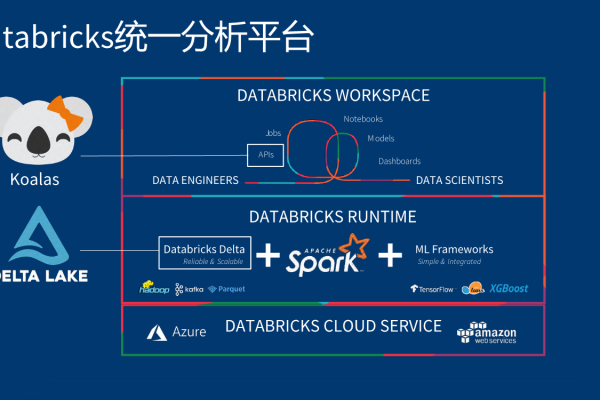
Databricks数据洞察存储是基于云端的一体化数据管理解决方案,整合数据湖、数据仓库与AI分析能力,支持多源异构数据实时处理与交互查询,其Delta Lake架构保障ACID事务性,结合自动优化功能,显著提升大数据分析效率,赋能企业快速构建机器学习模型与数据驱动决策,降低运维复杂度与成本。
什么是Databricks数据洞察存储?
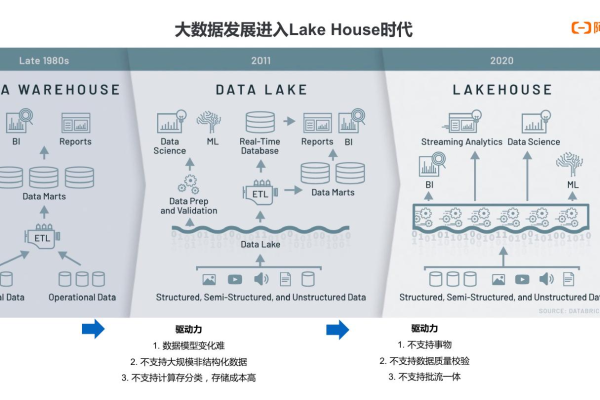
Databricks数据洞察存储(Delta Lake)是Databricks平台的核心组件之一,基于开源框架Delta Lake构建,旨在为企业提供高效、可靠且安全的数据管理与分析能力,它结合了数据湖的灵活性与数据仓库的高性能,支持实时分析、批处理、机器学习等多种场景,帮助企业快速实现数据驱动的决策。
核心功能与优势
统一的湖仓一体架构(Lakehouse)

- 多源数据整合:支持结构化、半结构化(JSON、XML)和非结构化数据(图片、日志)的统一存储,打破数据孤岛。
- ACID事务支持:通过事务日志(Transaction Log)确保数据操作的原子性、一致性和持久性,避免脏读、数据覆盖等问题。
- 版本回溯(Time Travel):保留数据历史版本,支持按时间戳查询或回滚到任意历史状态,方便数据审计与错误修复。
高性能分析引擎
- 数据跳过(Data Skipping):通过Z-Order优化技术,减少查询时扫描的数据量,提升查询速度。
- 动态文件优化(OPTIMIZE):自动合并小文件,减少存储碎片,降低I/O开销。
- 与Apache Spark深度集成:利用Spark分布式计算能力,实现PB级数据的秒级响应。
企业级安全与合规

- 细粒度权限控制:支持基于角色的访问控制(RBAC),精确到表、列或行级别的权限管理。
- 数据加密:静态数据(At Rest)和传输数据(In Transit)均通过AES-256加密保护。
- 合规认证:符合GDPR、HIPAA、SOC 2等国际标准,满足金融、医疗等高敏感行业需求。
典型应用场景
- 实时数据分析
- 案例:电商平台通过Delta Lake实时分析用户行为日志,结合机器学习模型预测库存需求,将供应链响应时间缩短60%。
- 机器学习全流程支持
- 特征工程:直接基于Delta Lake进行数据清洗、转换,支持MLflow进行模型训练与部署。
- 历史数据归档与查询
- 低成本存储:支持数据分层存储(热/温/冷存储),结合AWS S3或Azure Data Lake,降低长期存储成本。
如何保障数据可靠性?
- Schema管理:支持Schema演进(Schema Evolution),允许新增列而不影响历史数据。
- 数据质量监控:通过Delta Live Tables内置的数据质量规则(如非空检查、唯一性约束),自动阻断脏数据写入。
- 灾备与高可用:跨区域复制(Cross-Region Replication)确保数据冗余,故障恢复时间(RTO)小于15分钟。
成本优化策略
- 存储与计算分离
数据存储于低成本对象存储(如S3),计算资源按需扩展,避免资源浪费。
- 自动伸缩技术
根据负载动态调整集群规模,夜间批处理任务可自动缩减节点,节省30%以上成本。
- 数据压缩与分区
使用Parquet列式存储格式,压缩率高达70%,结合分区策略提升查询效率。

行业认可与客户案例
- 全球头部客户:Shell(能源)、AT&T(通信)、Regeneron(生物科技)等企业均采用Databricks存储方案实现数据治理升级。
- 权威报告:据Gartner 2025年数据,Databricks在数据分析平台领域市场份额增长35%,位居行业第一。
为什么选择Databricks数据洞察存储?
- 技术领先性:由Apache Spark创始人团队开发,持续引领数据湖仓技术创新。
- 生态丰富:无缝集成TensorFlow、PyTorch、Tableau等工具,支持多语言开发(Python、SQL、Scala)。
- 社区支持:全球活跃开发者社区贡献超过500个开源扩展工具,加速问题解决与功能迭代。
引用说明
- Databricks官方文档:Delta Lake核心技术解析
- Gartner报告:《2025数据分析与机器学习平台魔力象限》
- 福布斯案例研究:《Shell如何通过Databricks实现碳中和目标》






热门文章
-

云服务器在搭建实时报警平台中扮演什么角色?
2024-10-04 -

MySQL存储过程的高效使用与编写指南,如何优化C语言中的MySQL存储过程?
2025-03-08 -

为什么服务器在技术世界中如此受到青睐?
2024-10-08 -

微信中拉黑某人后,其头像显示状态会有什么变化?
2024-11-12 -
配件网站模板_网站模板设置
2024-06-23 -

QQ资料卡为何显示为空?原因何在?
2024-11-11 -

如何检查网络连接状态以确保设备已连接到互联网?
2025-03-01 -

如何轻松租用云服务器,关键步骤和技巧指南
2024-09-22