服务器启动新进程后为何频繁卡顿?

服务器开启新进程后出现卡顿通常由资源不足或配置不当引起,可能原因包括CPU过载、内存不足、磁盘I/O瓶颈,或进程优先级设置不合理,建议检查系统资源使用情况,优化服务配置,关闭冗余进程,必要时升级硬件组件或排查潜在反面程序。
服务器后开进程卡顿的原因与解决方案
当服务器在启动新进程时出现卡顿,可能影响业务运行效率和用户体验,这一问题通常由资源竞争、配置不足或代码缺陷引发,以下是系统性分析与应对方法,帮助管理员快速定位并解决问题。
常见原因与排查步骤
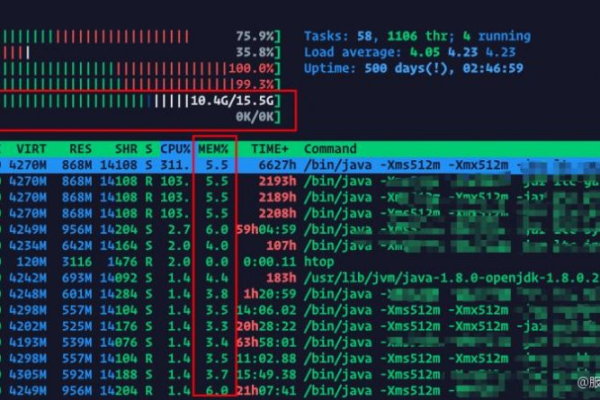
资源瓶颈

- CPU过载:新进程启动需占用CPU资源,若当前负载已饱和,会导致排队延迟。
排查工具:top、htop、vmstat(观察%us用户态CPU使用率)。 - 内存不足:进程初始化时申请内存失败,触发频繁交换(Swap)或OOM Killer强制终止进程。
排查工具:free -h、vmstat -s(关注剩余内存与Swap使用量)。 - 磁盘I/O阻塞:日志写入、数据库操作等依赖磁盘的进程可能因I/O延迟卡顿。
排查工具:iostat、iotop(检查await和%util指标)。
- CPU过载:新进程启动需占用CPU资源,若当前负载已饱和,会导致排队延迟。
进程冲突
- 端口占用:新进程尝试绑定已被占用的端口,导致启动失败或重试延迟。
排查命令:netstat -tulnp | grep <端口号>。 - 锁竞争:文件锁、数据库锁等资源被其他进程持有,引发等待。
排查方法:检查日志中Lock wait timeout等关键字。
- 端口占用:新进程尝试绑定已被占用的端口,导致启动失败或重试延迟。
代码与配置问题

- 初始化脚本缺陷:启动脚本包含低效循环、未处理的异常或依赖服务未就绪。
- JVM/应用配置不当:例如Java堆内存过小(
-Xmx参数)、线程池大小不合理。 - 依赖服务响应慢:如数据库连接超时、第三方API延迟。
针对性解决方案
资源优化
- 调整进程优先级:通过
nice或renice命令降低非关键进程的CPU优先级,保障核心任务资源。 - 限制资源占用:使用
cgroups(控制组)隔离进程的CPU、内存和I/O使用上限。 - 升级硬件配置:若长期存在资源瓶颈,考虑扩展CPU核心、增加内存或使用SSD磁盘。
进程管理与调度

- 异步启动:将非紧急进程的启动延迟至低峰期,或采用后台任务模式(如
nohup)。 - 端口冲突处理:通过
lsof定位占用端口的进程,并终止或修改其配置。 - 锁优化:缩短锁持有时间、改用非阻塞锁或引入分布式锁机制(如Redis)。
代码与配置调整
- 优化启动脚本:移除冗余操作,添加超时重试机制,确保依赖服务就绪后再启动。
- 调整JVM参数:根据服务器内存设置合理的堆大小(例如
-Xmx4g)和垃圾回收策略。 - 启用缓存与连接池:减少数据库查询和网络请求次数,预加载高频访问数据。
预防与长期优化
- 监控预警
部署Prometheus+Grafana或Zabbix,实时监控CPU、内存、磁盘I/O等指标,设置阈值告警。 - 压测与容量规划
使用JMeter或LoadRunner模拟高并发场景,评估服务器承载能力并提前扩容。 - 日志分析
集中管理日志(如ELK栈),通过关键词过滤(如Timeout、Deadlock)快速定位异常。
高级技巧与工具推荐
- 火焰图分析:通过
perf或FlameGraph生成CPU使用热点图,定位代码级性能瓶颈。 - 内核参数调优:调整
vm.swappiness(降低Swap倾向)、net.core.somaxconn(优化TCP连接队列)。 - 容器化部署:使用Docker或Kubernetes隔离进程资源,避免环境依赖冲突。
引用说明
本文参考了Linux内核文档、Oracle JVM调优指南及《Systems Performance: Enterprise and the Cloud》中的技术实践,结合一线运维经验总结而成。



热门文章
-

云服务器在搭建实时报警平台中扮演什么角色?
2024-10-04 -

MySQL存储过程的高效使用与编写指南,如何优化C语言中的MySQL存储过程?
2025-03-08 -

为什么服务器在技术世界中如此受到青睐?
2024-10-08 -

微信中拉黑某人后,其头像显示状态会有什么变化?
2024-11-12 -
配件网站模板_网站模板设置
2024-06-23 -

QQ资料卡为何显示为空?原因何在?
2024-11-11 -

如何检查网络连接状态以确保设备已连接到互联网?
2025-03-01 -

如何轻松租用云服务器,关键步骤和技巧指南
2024-09-22