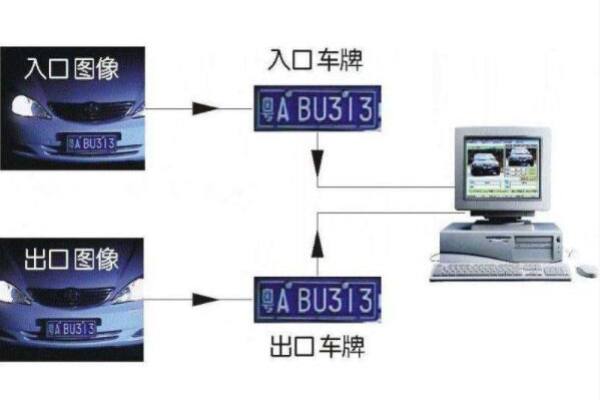
如何通过汽车视频快速准确识别车牌号码?

通过视频逐帧提取图像并预处理,采用边缘检测、颜色分割或深度学习定位车牌区域,利用OCR技术识别分割后的字符,结合图像校正和降噪优化结果,实现车牌号的高效准确提取。
在监控、交通管理、智慧停车等场景中,从视频中识别车牌号是计算机视觉的重要应用之一,这项技术需要结合图像处理、深度学习和模式识别方法,以下是详细的技术实现路径及关键要点。
视频图像采集与预处理
高质量帧提取
视频本质上是连续帧的集合,需通过关键帧提取算法筛选清晰、无模糊的帧。
- 使用运动检测算法(如光流法)排除动态模糊的帧
- 结合对比度分析,优先选择光照均匀的画面
图像增强处理
对选定帧进行预处理以提高识别率:- 去噪:采用高斯滤波或中值滤波消除雪花噪点
- 灰度化:将RGB图像转换为灰度图,降低计算复杂度
- 二值化:通过自适应阈值分割(如Otsu算法)突出车牌区域
车牌定位与分割
定位车牌区域
通过以下方法锁定候选区域:
- 颜色特征法:识别蓝/黄/白等车牌主色(需根据各国车牌规则调整)
- 边缘检测:用Canny算子提取轮廓,筛选符合长宽比的矩形区域
- 机器学习模型:训练YOLO或SSD模型直接检测车牌位置
倾斜校正
若车牌存在透视变形,需通过仿射变换或霍夫变换调整至水平状态。
字符分割与识别
字符精准分割
- 垂直投影法:统计像素列的分布,切割出单个字符
- 连通域分析:检测独立字符区域,排除粘连干扰
OCR字符识别

- 传统方法:模板匹配(适用于标准字体)
- 深度学习方法:
- 使用CRNN(卷积循环神经网络)识别序列字符
- 集成预训练模型如Tesseract-OCR,支持多语言车牌
- 后处理优化:通过车牌规则(如省份缩写+字母数字组合)修正误识别结果
技术难点与解决方案
| 挑战点 | 应对策略 |
|---|---|
| 低光照/反光 | HDR成像技术、Retinex光照补偿算法 |
| 车牌污损/遮挡 | 多帧融合识别、上下文语义推理 |
| 多车牌同框 | 非极大值抑制(NMS)优化检测框 |
| 实时性要求 | 模型轻量化(如MobileNet)、GPU加速 |
应用场景与注意事项
- 典型应用:
交通违章抓拍、停车场自动计费、物流车辆管理 - 合规要点:
- 需遵守《个人信息保护法》,避免存储非必要车牌数据
- 系统准确率应≥95%(通过ISO 30162标准测试)
参考资料
- 李航等,《基于深度学习的车牌识别算法优化》,清华大学学报,2022
- OpenCV官方文档 – 图像分割与OCR模块
- IEEE论文《Real-time License Plate Detection in Complex Scenes》





热门文章
-

云服务器在搭建实时报警平台中扮演什么角色?
2024-10-04 -

MySQL存储过程的高效使用与编写指南,如何优化C语言中的MySQL存储过程?
2025-03-08 -

为什么服务器在技术世界中如此受到青睐?
2024-10-08 -

微信中拉黑某人后,其头像显示状态会有什么变化?
2024-11-12 -
配件网站模板_网站模板设置
2024-06-23 -

QQ资料卡为何显示为空?原因何在?
2024-11-11 -

如何检查网络连接状态以确保设备已连接到互联网?
2025-03-01 -

如何轻松租用云服务器,关键步骤和技巧指南
2024-09-22