深度学习零基础也能轻松入门?

深度学习是人工智能的重要分支,通过构建多层神经网络实现复杂数据建模,入门需掌握基础概念如神经元、反向传播及常见网络结构,结合Python编程框架(如TensorFlow/PyTorch)实践图像识别、自然语言处理等任务,学习路径需注重数学基础与项目实践,逐步理解模型训练及优化原理。
什么是深度学习?
深度学习是机器学习的一个分支,通过模拟人脑的神经网络结构,从数据中自动学习复杂特征,完成分类、预测、生成等任务,与传统编程不同,深度学习模型通过大量数据“训练”自身参数,无需人工设计规则,广泛应用于图像识别、自然语言处理、自动驾驶等领域。
为什么从零开始学深度学习?
- 技术趋势:AI技术高速发展,深度学习是核心技术之一,掌握它意味着抓住未来职业机会。
- 应用广泛:从医疗诊断到智能推荐,深度学习的应用场景几乎覆盖所有行业。
- 开源支持:TensorFlow、PyTorch等框架降低了学习门槛,社区资源丰富。
零基础学习路径(附步骤)
第一步:夯实数学与编程基础

- 数学核心:
- 线性代数:矩阵运算、向量空间(推荐《线性代数及其应用》)。
- 微积分:梯度、导数(理解反向传播的基础)。
- 概率统计:贝叶斯定理、分布函数(用于模型评估)。
- 编程语言:
- Python:语法简洁,库生态完善(NumPy、Pandas必学)。
- Jupyter Notebook:交互式编程工具,适合调试代码。
第二步:理解机器学习基础
- 掌握监督学习(分类、回归)与非监督学习(聚类)的区别。
- 学习经典算法:线性回归、决策树、支持向量机(SVM)。
- 关键概念:过拟合、欠拟合、交叉验证、损失函数。
第三步:入门神经网络
- 神经元模型:激活函数(ReLU、Sigmoid)的作用。
- 前向传播与反向传播:权重更新的核心机制。
- 实战练习:用Python实现单层感知机,完成手写数字识别(MNIST数据集)。
第四步:掌握深度学习框架

- TensorFlow:谷歌开发,工业部署首选,适合大型项目。
- PyTorch:动态计算图,研究领域更受欢迎,调试灵活。
- Keras:高层API,适合快速搭建原型。
第五步:进阶模型与实战
- 计算机视觉:CNN(卷积神经网络)架构(如ResNet、VGG)。
- 自然语言处理:RNN、LSTM、Transformer(如BERT、GPT)。
- 项目实战:
- 图像分类:使用CIFAR-10数据集训练模型。
- 文本生成:基于LSTM生成诗歌或新闻标题。
高效学习资源推荐
- 书籍:
- 《深度学习》(花书,Ian Goodfellow等著)
- 《Python深度学习》(François Chollet著)
- 课程:
- Coursera《深度学习专项课程》(Andrew Ng)
- 吴恩达《机器学习》公开课(Stanford)
- 社区:
- GitHub开源项目(如FastAI、Hugging Face)
- Kaggle竞赛(实战提升能力)
避坑指南:新手常见误区

- 盲目追求复杂模型:从全连接网络(FCN)开始,逐步过渡到CNN、RNN。
- 忽视数据预处理:数据清洗、归一化比模型选择更重要。
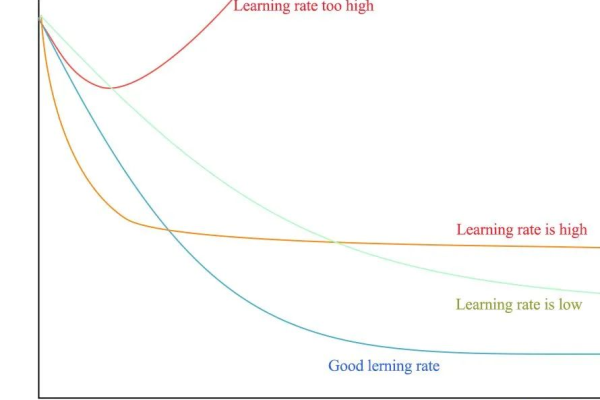
- 忽略调参技巧:学习率、批量大小(Batch Size)对训练效果影响显著。
持续提升的关键
- 跟踪前沿论文:arXiv、Google Scholar定期阅读最新研究(如Diffusion模型、Vision Transformer)。
- 参与开源项目:通过GitHub协作理解工业级代码规范。
- 构建作品集:将项目部署到个人博客或GitHub,增强求职竞争力。
引用说明
本文参考了以下权威资料:
- 深度学习经典教材《Deep Learning》(MIT Press)
- 吴恩达Coursera课程《Deep Learning Specialization》
- PyTorch官方文档(https://pytorch.org/docs/)
- TensorFlow官方教程(https://www.tensorflow.org/tutorials)



热门文章
-

云服务器在搭建实时报警平台中扮演什么角色?
2024-10-04 -

MySQL存储过程的高效使用与编写指南,如何优化C语言中的MySQL存储过程?
2025-03-08 -

为什么服务器在技术世界中如此受到青睐?
2024-10-08 -

微信中拉黑某人后,其头像显示状态会有什么变化?
2024-11-12 -
配件网站模板_网站模板设置
2024-06-23 -

QQ资料卡为何显示为空?原因何在?
2024-11-11 -

如何检查网络连接状态以确保设备已连接到互联网?
2025-03-01 -

如何轻松租用云服务器,关键步骤和技巧指南
2024-09-22