服务器竟能自动停机?揭秘背后隐藏的惊人真相!

服务器可以自己停吗?
在日常运维中,服务器“自己停止运行”的现象确实可能发生,这一问题的成因复杂,既可能源自内部软硬件故障,也可能与外部环境或人为操作相关,以下从技术角度详细分析可能的原因,并提供针对性解决方案。
服务器“自动停止”的常见原因
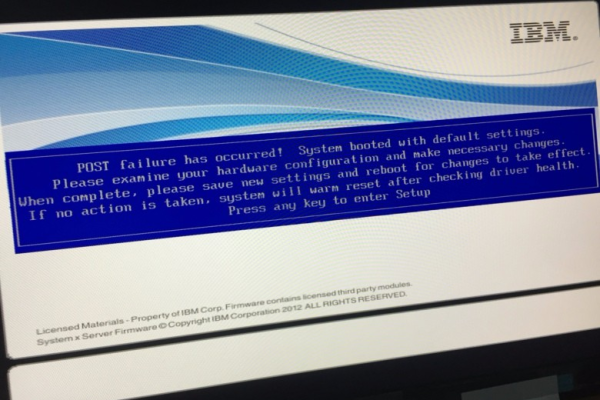
硬件故障
- 电源问题:供电不稳定、电源模块损坏可能导致服务器突然断电。
- 散热故障:CPU或硬盘温度过高触发系统保护机制,强制关机。
- 硬盘损坏:物理坏道或SSD寿命耗尽,导致系统崩溃。
软件或系统错误
- 操作系统崩溃:内核级错误、驱动不兼容等问题可能引发系统宕机。
- 服务进程冲突:如Web服务器(Nginx/Apache)与数据库(MySQL)资源竞争导致死锁。
- 计划任务误操作:错误配置的定时任务(如
shutdown命令)可能意外关闭服务器。
资源耗尽
- 内存不足:高并发场景下内存耗尽,触发OOM Killer强制终止进程甚至重启。
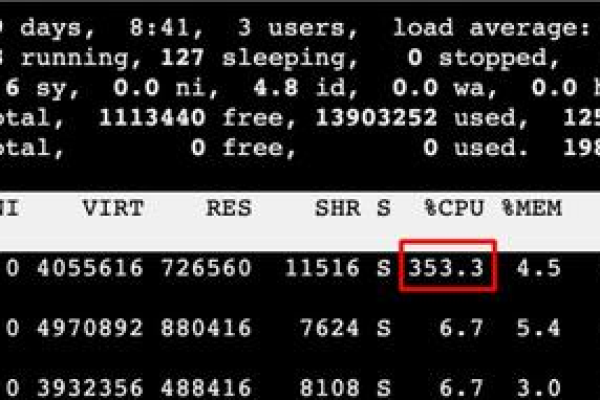
- CPU过载:持续100%占用可能引发系统无响应。
- 磁盘空间占满:日志文件或临时数据未清理,导致关键服务停止。
外部攻击或安全机制

- DDoS攻击:流量洪峰导致服务器无法响应,被迫下线。
- 安全防护拦截:防火墙误判合法流量为攻击,阻断服务访问。
- 许可证过期:部分商业软件(如Windows Server)授权到期后可能限制功能。
人为操作与配置失误
- 远程误操作:通过SSH或管理面板误执行关机指令。
- 自动化脚本错误:运维脚本逻辑缺陷可能触发非预期关机。
解决方案与预防措施
实时监控与告警
- 部署Zabbix、Prometheus等工具监控CPU、内存、磁盘、温度等指标。
- 设置阈值告警(如CPU>90%持续5分钟),通过短信、邮件通知运维人员。
硬件冗余与灾备
- 采用双电源、RAID磁盘阵列、冗余风扇等设计。
- 配置UPS(不间断电源)应对突发断电。
- 使用负载均衡将流量分发至多台服务器,避免单点故障。
系统优化与维护
- 定期更新操作系统和软件补丁(如Linux的
yum update)。 - 配置日志轮转(如
logrotate)避免磁盘空间占满。 - 限制非必要后台进程,通过
cgroups控制资源分配。
- 定期更新操作系统和软件补丁(如Linux的
安全防护强化

- 部署云防火墙(如阿里云WAF)防御DDoS/CC攻击。
- 启用Fail2ban屏蔽异常登录尝试。
- 定期审计账户权限,避免未授权操作。
容灾与快速恢复
- 制定RTO(恢复时间目标)和RPO(数据恢复点目标)。
- 使用快照备份(如AWS EC2 Snapshot)实现分钟级回滚。
- 编写应急预案,涵盖从硬件更换到数据恢复的全流程。
如何判断服务器停机的具体原因?
查看系统日志
- Linux系统通过
journalctl -b -1查看上次启动日志。 - Windows系统检查“事件查看器”中的关键错误代码(如Kernel-Power 41)。
- Linux系统通过
分析性能趋势
- 使用
sar(System Activity Reporter)回顾历史资源使用情况。 - 通过
dmesg检查内核级报错信息。
- 使用
联系服务商协助
- 云服务器用户可通过控制台查看服务商侧监控数据(如AWS CloudWatch)。
- 物理服务器可要求IDC机房提供电力、网络链路检测报告。
用户常见疑问解答
Q:云服务器会比物理机更稳定吗?
A:云服务商通常提供99.95%以上的SLA保障,但虚拟机仍可能受宿主物理机故障影响,建议结合多可用区部署。
Q:服务器自动关机后数据会丢失吗?
A:若未配置持久化存储,内存中的临时数据可能丢失,建议关键业务使用带电池缓存的RAID卡或分布式存储(如Ceph)。
服务器自动停机是多重因素综合作用的结果,通过事前监控、事中响应、事后复盘的全周期管理,可显著降低风险,根据行业统计,完善监控体系可将意外停机时间减少70%以上(数据来源:Gartner 2025报告)。
引用说明
本文技术细节参考《Linux服务器运维实战》(清华大学出版社,2022),云服务SLA数据来源于AWS官方文档,行业统计数据引自Gartner报告《Global IT Infrastructure Trends 2025》。


热门文章
-

云服务器在搭建实时报警平台中扮演什么角色?
2024-10-04 -

MySQL存储过程的高效使用与编写指南,如何优化C语言中的MySQL存储过程?
2025-03-08 -

为什么服务器在技术世界中如此受到青睐?
2024-10-08 -

微信中拉黑某人后,其头像显示状态会有什么变化?
2024-11-12 -
配件网站模板_网站模板设置
2024-06-23 -

QQ资料卡为何显示为空?原因何在?
2024-11-11 -

如何检查网络连接状态以确保设备已连接到互联网?
2025-03-01 -

如何轻松租用云服务器,关键步骤和技巧指南
2024-09-22