如何构建一个数据仓库,实例解析

创建数据仓库是一个复杂但有序的过程,涉及数据的提取、转换和加载(ETL),以及数据建模和优化,以下是一个详细的步骤示例,展示如何创建一个数据仓库。
确定业务需求
在开始任何技术工作之前,首先需要明确业务需求,这包括了解公司希望通过数据仓库解决的具体问题或实现的目标,一个零售公司可能希望分析销售趋势、库存管理和客户行为。
选择数据源
确定需要集成的数据源,这些数据源可能包括:
关系数据库(如MySQL, PostgreSQL)
事务处理系统(如ERP系统)
日志文件和CSV文件
外部数据(如市场数据)
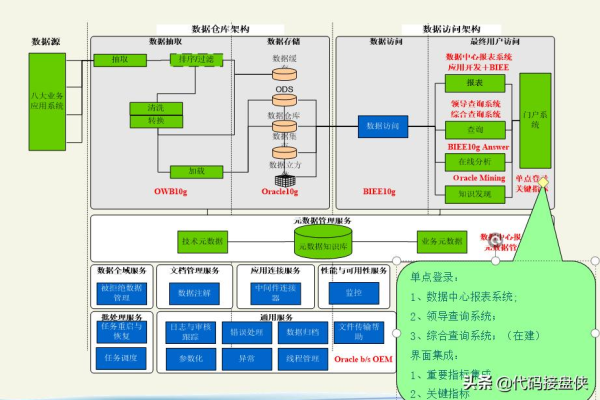
设计数据仓库架构
3.1 数据仓库模型
常见的数据仓库模型有星型模式和雪花模式,星型模式是最常用的,它包括一个事实表和多个维度表。
3.2 事实表和维度表
事实表:存储量化的业务数据,例如销售额、订单数量等。
维度表:存储描述性数据,例如时间、地理位置、产品类别等。
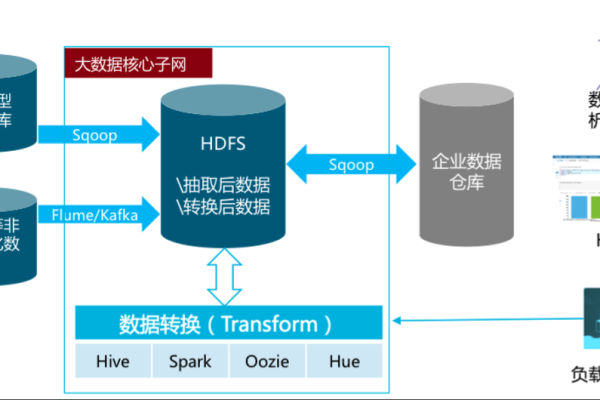
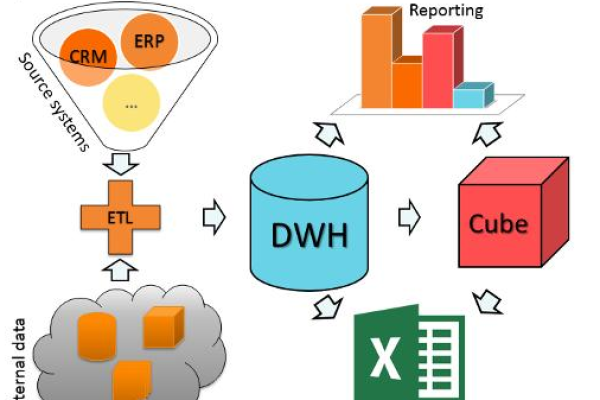
ETL过程
ETL过程包括三个主要步骤:提取(Extract)、转换(Transform)和加载(Load)。
4.1 提取

从各个数据源中提取数据,可以使用各种工具和技术,
SQL查询
数据导入/导出工具
API调用
4.2 转换
对提取的数据进行清洗和转换,以确保数据质量,这通常包括以下操作:
数据清洗:去除重复数据、处理缺失值等
数据转换:将数据格式标准化,例如日期格式转换
数据聚合:根据业务需求进行数据汇总
4.3 加载

将转换后的数据加载到数据仓库中,可以使用批量加载工具或者实时流处理框架,如Apache Kafka。
数据建模和物理设计
5.1 数据建模
使用ER图或其他建模工具来设计数据仓库的逻辑结构,确保模型能够支持复杂的查询和数据分析。
5.2 物理设计
选择合适的存储引擎和索引策略,以优化查询性能,可以选择列式存储引擎如Apache HBase或行式存储引擎如MySQL。
实现和测试
6.1 实现
使用选定的技术栈实现数据仓库,可以使用Hadoop生态系统中的Hive或Spark SQL来构建数据仓库。
6.2 测试
进行全面的测试,包括单元测试、集成测试和性能测试,确保数据仓库能够满足业务需求并且性能良好。
部署和维护
7.1 部署
将数据仓库部署到生产环境,确保有备份和恢复机制,以防止数据丢失。
7.2 维护

定期监控数据仓库的性能,进行必要的优化和扩展,更新ETL流程以适应新的数据源和业务需求。
用户培训和支持
为用户提供培训和支持,帮助他们有效地使用数据仓库进行数据分析和决策支持。
相关问答FAQs
Q1: 数据仓库和传统数据库有什么区别?
A1: 数据仓库主要用于分析和报告,而传统数据库主要用于事务处理,数据仓库通常存储历史数据,支持复杂的查询和数据分析,而传统数据库则侧重于实时事务处理和数据一致性。
Q2: 如何选择适合的数据仓库工具?
A2: 选择数据仓库工具时,需要考虑以下因素:
数据量和复杂度:大数据量和复杂查询可能需要分布式计算框架如Hadoop或Spark。
实时性要求:如果需要实时分析,可以考虑使用实时流处理框架如Apache Kafka或Flink。
成本和可扩展性:开源工具如Apache Hadoop和Spark通常成本较低且具有良好的可扩展性。
技术支持和社区活跃度:选择有良好技术支持和活跃社区的工具,可以获得更多的资源和支持。
小编有话说
创建数据仓库是一个持续的过程,需要不断地优化和维护,通过明确的业务需求、合理的架构设计和高效的ETL流程,可以构建一个强大且灵活的数据仓库,为企业提供有价值的数据分析和决策支持,希望这篇文章能够帮助你理解并实施数据仓库项目,如果你有任何问题或建议,欢迎留言讨论!




热门文章
-

云服务器在搭建实时报警平台中扮演什么角色?
2024-10-04 -

MySQL存储过程的高效使用与编写指南,如何优化C语言中的MySQL存储过程?
2025-03-08 -

为什么服务器在技术世界中如此受到青睐?
2024-10-08 -

微信中拉黑某人后,其头像显示状态会有什么变化?
2024-11-12 -
配件网站模板_网站模板设置
2024-06-23 -

QQ资料卡为何显示为空?原因何在?
2024-11-11 -

如何检查网络连接状态以确保设备已连接到互联网?
2025-03-01 -

如何轻松租用云服务器,关键步骤和技巧指南
2024-09-22