如何高效利用Databricks数据洞察优化分析流程?

Databricks数据洞察使用流程包括数据接入、集群配置、交互式分析及协作开发,用户通过统一平台完成数据导入、清洗处理、模型训练与可视化,支持多语言编程及团队协作,结合云端资源实现自动化运维,助力企业快速完成大数据处理与AI分析任务。
Databricks数据洞察使用流程
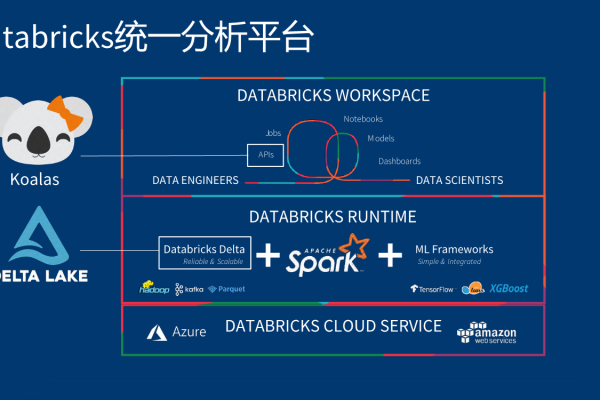
Databricks数据洞察(Databricks Data Insights)是基于Apache Spark的云原生数据分析平台,支持企业快速处理大规模数据并实现智能决策,以下是详细的使用流程,帮助用户从零开始高效上手。
注册与账号配置
- 访问官网
登录Databricks官方网站,点击“免费试用”或“立即注册”创建账号(可选择个人版或企业版)。 - 选择云服务商
根据需求绑定AWS、Azure或Google Cloud账号,完成云资源授权。 - 创建工作区(Workspace)
在控制台创建团队协作空间,设定名称、区域和计算资源配置(建议初始选择默认配置)。
数据准备与导入

- 上传数据源
- 通过本地文件上传:支持CSV、JSON、Parquet等格式。
- 连接外部数据库:如MySQL、Snowflake、Redshift等,配置JDBC/ODBC参数。
- 集成云存储:直接读取AWS S3、Azure Blob中的文件。
- 加载数据到工作区
使用DBUtils工具或Spark API(如spark.read.csv())将数据加载至Databricks表(Delta Lake格式)。 - 数据预处理
- 使用Notebook编写Python/SQL脚本清洗数据(去重、填充缺失值)。
- 利用AutoML功能自动生成特征工程代码。
数据分析与建模
- 交互式分析
- 在Notebook中运行SQL查询:
%sql SELECT * FROM table LIMIT 10。 - 创建可视化图表:通过内置的图表工具或集成Tableau/Power BI生成仪表盘。
- 在Notebook中运行SQL查询:
- 机器学习建模
- 调用MLflow跟踪实验:记录超参数、指标和模型版本。
- 使用预置算法库:如Spark MLlib训练分类/回归模型。
- 部署模型:通过REST API将模型发布为服务。
协作与共享
- 团队协作
- 邀请成员加入工作区,分配角色(管理员、开发者、只读用户)。
- 通过Git集成同步代码至GitHub/GitLab。
- 文档与结果共享
- 导出Notebook为HTML或PDF报告。
- 使用Databricks Jobs定时运行任务并邮件通知结果。
运维与优化

- 集群管理
- 按需创建/终止集群:根据负载选择标准版或高并发模式。
- 启用自动伸缩(Autoscaling):动态调整节点数量以节省成本。
- 监控与告警
- 通过Dashboard查看集群CPU/内存使用率。
- 设置阈值告警(如任务失败或资源超限)。
成本控制
- 预算管理
- 在云服务商控制台设置月度预算上限。
- 使用Databricks的成本分析工具优化资源配置(如选择Spot实例)。
- 资源回收
关闭闲置集群,清理临时表和历史快照。
Databricks数据洞察通过统一的平台简化了数据工程、分析和机器学习的全流程,无论是初创团队还是大型企业,均可借助其弹性计算能力和自动化工具降低运维复杂度,专注于业务价值挖掘。

引用说明
本文参考了Databricks官方文档(2025版)及AWS/Azure云服务的最佳实践指南,确保内容符合技术标准与行业规范。




热门文章
-

云服务器在搭建实时报警平台中扮演什么角色?
2024-10-04 -

MySQL存储过程的高效使用与编写指南,如何优化C语言中的MySQL存储过程?
2025-03-08 -

为什么服务器在技术世界中如此受到青睐?
2024-10-08 -

微信中拉黑某人后,其头像显示状态会有什么变化?
2024-11-12 -
配件网站模板_网站模板设置
2024-06-23 -

如何检查网络连接状态以确保设备已连接到互联网?
2025-03-01 -

如何轻松租用云服务器,关键步骤和技巧指南
2024-09-22 -

QQ资料卡为何显示为空?原因何在?
2024-11-11