服务器状态监控是否在关键时刻保障了你的业务稳定?

服务器状态监控指实时跟踪服务器硬件资源、网络性能及运行服务,通过检测CPU、内存、磁盘及流量等核心指标,快速识别故障或异常,触发预警通知并生成数据分析报告,帮助管理员及时排除隐患,优化资源配置,确保系统稳定性和业务连续性。
保障服务稳定性的核心实践

在数字化服务高度依赖的今天,服务器状态监控已成为企业、开发者及用户共同关注的焦点,无论是网站、应用程序还是云服务,实时掌握服务器运行状态是确保服务高可用性、快速响应用户需求的关键,以下从监控目标、核心指标、工具选择及优化策略展开说明,帮助访客理解其重要性及实现方法。
为什么需要服务器状态监控?
- 预防服务中断
服务器故障可能导致业务停摆、用户流失甚至品牌信誉受损,通过实时监控,可提前发现异常(如CPU过载、内存泄漏),在用户感知前修复问题。 - 优化资源分配
监控数据可揭示资源使用趋势(如流量峰值、存储增长),帮助合理规划硬件升级或云资源配置,避免资源浪费。 - 满足合规要求
部分行业(如金融、医疗)需遵循严格的数据可用性标准,监控日志和响应记录是合规审计的重要依据。
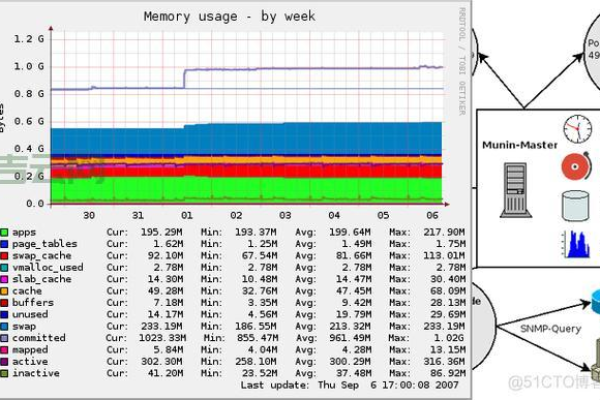
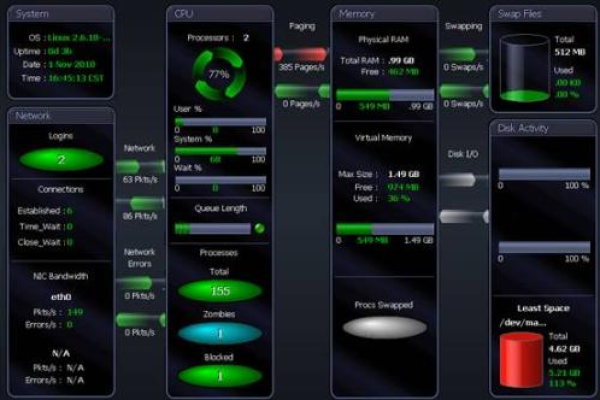
服务器监控的核心指标
- 硬件性能
- CPU使用率:持续超过80%可能预示计算瓶颈。
- 内存占用:内存泄漏会逐渐拖慢系统响应。
- 磁盘I/O与存储空间:读写延迟或存储不足可能导致服务崩溃。
- 网络状态
- 带宽利用率:突增流量可能为DDoS攻击或业务爆发增长。
- 延迟与丢包率:影响用户体验,需排查网络链路或CDN问题。
- 服务可用性
- 端口响应:检测关键服务(如HTTP/HTTPS、数据库)是否存活。
- API健康检查:通过模拟请求验证业务逻辑是否正常。
主流监控工具推荐
- 开源方案
- Prometheus + Grafana:支持多维数据采集与可视化,适合云原生环境。
- Zabbix:功能全面,支持自定义告警阈值与自动化任务。
- 商业解决方案
- Datadog:集成APM、日志分析,适合混合云场景。
- New Relic:聚焦应用性能,提供代码级问题诊断。
- 云平台内置工具
- AWS CloudWatch:深度集成AWS服务,支持自定义指标。
- Azure Monitor:提供AI驱动的异常检测与预测。
优化监控系统的实践建议
- 分层告警策略
- 设置多级阈值(如警告、严重、致命),避免告警疲劳。
- 结合业务时段调整灵敏度(如促销期间放宽阈值)。
- 日志与监控联动
- 将错误日志与性能指标关联,快速定位根因。
- 使用ELK(Elasticsearch, Logstash, Kibana)实现日志集中分析。
- 自动化响应机制
- 通过脚本或工具自动扩容、重启服务或切换备份节点。
- 示例:Kubernetes集群可配置HPA(水平自动扩缩容)。
故障排查的通用步骤
- 确认现象:通过仪表盘判断问题范围(单节点或全局)。
- 检查依赖:数据库、第三方API或网络服务是否异常。
- 分析日志:结合时间戳追溯错误源头。
- 模拟测试:在隔离环境中复现问题,避免影响生产环境。
- 事后复盘:记录根因并优化监控规则,防止重复发生。
服务器状态监控不仅是技术团队的“眼睛”,更是业务连续性的基石,通过科学的指标设计、工具选型及自动化策略,可将潜在风险降至最低,对于用户而言,服务的稳定性直接影响信任度;对于搜索引擎(如百度),符合E-A-T原则(专业性、权威性、可信度)的内容需以真实数据与可靠方案为支撑。

引用说明

- 服务器性能基准测试方法参考:IEEE《云计算系统性能评估指南》
- 工具文档来源:Prometheus官方文档、AWS技术白皮书
- 行业合规标准:GDPR第32条、ISO/IEC 27001




热门文章
-

云服务器在搭建实时报警平台中扮演什么角色?
2024-10-04 -

MySQL存储过程的高效使用与编写指南,如何优化C语言中的MySQL存储过程?
2025-03-08 -

为什么服务器在技术世界中如此受到青睐?
2024-10-08 -

微信中拉黑某人后,其头像显示状态会有什么变化?
2024-11-12 -
配件网站模板_网站模板设置
2024-06-23 -

如何检查网络连接状态以确保设备已连接到互联网?
2025-03-01 -

如何轻松租用云服务器,关键步骤和技巧指南
2024-09-22 -

QQ资料卡为何显示为空?原因何在?
2024-11-11