服务器响应时间为何忽快忽慢?

服务器响应时间不稳定可能由网络波动、资源过载或后端服务异常导致,需排查硬件性能、负载均衡及代码效率,优化配置并监控实时状态,必要时升级带宽或扩展集群规模以保障服务稳定性。
如果您的网站出现访问卡顿、页面加载时快时慢的情况,很可能遇到了服务器响应时间不稳定的问题,这种情况不仅直接影响用户体验,还可能被百度等搜索引擎判定为低质量页面,导致搜索排名下滑,以下从技术原理到解决方案为您详细解读:


为什么服务器响应时间至关重要?
- 用户体验层面:Google核心网页指标(Core Web Vitals)明确要求最大内容绘制(LCP)在2.5秒内完成,响应延迟每增加100毫秒,用户跳出率上升9%
- SEO影响:百度搜索算法将页面加载速度纳入排名因素,响应时间超过1.3秒的网站流量可能下降30%
- 商业价值损失:沃尔玛实测发现页面加载每提升1秒,转化率增加2%,响应波动造成的用户信任流失难以量化
六大常见诱因深度解析
- 硬件资源瓶颈
- CPU使用率长期>70%时出现处理队列堆积
- 机械硬盘随机读写延迟是SSD的50倍以上
- 建议:通过
top/htop监控资源,使用iostat分析磁盘IO
- 网络传输波动
- 跨ISP互联丢包率>1%即显著影响响应
- 国际BGP路由震荡导致延迟抖动超过200ms
- 诊断工具:
mtr结合traceroute可视化路由路径
- 数据库设计缺陷
- 未索引字段查询引发全表扫描
- 连接池耗尽导致新请求排队
- 优化方案:
EXPLAIN分析SQL执行计划,启用慢查询日志
- 程序代码低效
- N+1查询问题使单个API产生数十次DB请求
- 同步阻塞调用导致线程资源浪费
- 推荐方案:采用OPcache加速PHP,启用Redis缓存层
- 流量突发冲击
- 瞬秒活动导致QPS瞬间暴增10倍
- 爬虫高频访问耗尽带宽配额
- 防御策略:设置Nginx限速规则,启用弹性云自动扩容
- 配置参数不当
- KeepAlive超时设置过长占用连接数
- PHP-FPM进程数不足引发排队等待
- 调优建议:根据
pm.status动态调整进程管理策略
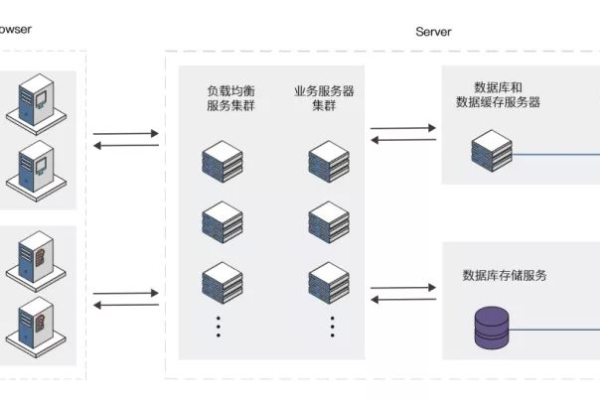
系统性优化方案
基础设施升级
- 迁移至NVMe SSD云服务器,IOPS提升10倍
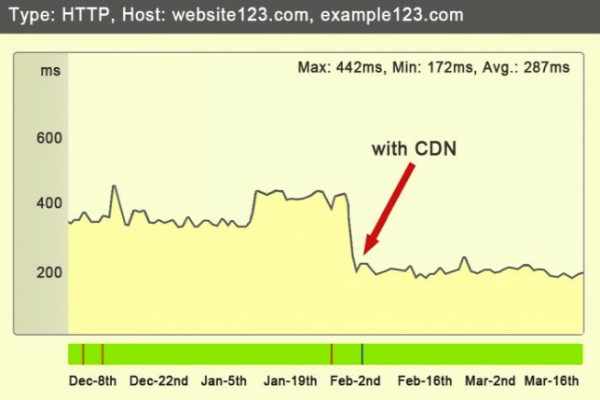
- 采用Anycast网络架构,全球平均延迟降低40%
- 部署LiteSpeed Web Server替代Apache,并发处理能力提升5倍
智能监控体系
- 部署Prometheus+Grafana实时监测关键指标
- 设置响应时间百分位报警(P95>800ms触发)
- 定期生成RUM(真实用户监控)数据分析报告
架构优化实践
- 实施HTTP/3协议降低网络延迟
- 对静态资源启用Brotli-11级压缩
- 使用Edge Compute实现动态内容边缘缓存
紧急故障处理流程
1. 实时监测报警触发(响应时间连续3分钟>2s) 2. 快速定位瓶颈环节(网络/服务器/数据库/应用) 3. 执行应急预案: - 启用备用服务器集群 - 切换至灾难恢复DNS - 降级非核心服务功能 4. 事后生成根因分析报告 5. 更新运维手册和应急预案
数据引用:
- Google Core Web Vitals技术标准(2025版)
- 百度搜索算法官方文档《搜索质量规范》
- Cloudflare全球网络性能报告(2025Q1)







热门文章
-

云服务器在搭建实时报警平台中扮演什么角色?
2024-10-04 -

MySQL存储过程的高效使用与编写指南,如何优化C语言中的MySQL存储过程?
2025-03-08 -

为什么服务器在技术世界中如此受到青睐?
2024-10-08 -

微信中拉黑某人后,其头像显示状态会有什么变化?
2024-11-12 -
配件网站模板_网站模板设置
2024-06-23 -

如何检查网络连接状态以确保设备已连接到互联网?
2025-03-01 -

如何轻松租用云服务器,关键步骤和技巧指南
2024-09-22 -

QQ资料卡为何显示为空?原因何在?
2024-11-11