服务器渣渣

现有服务器常因硬件性能不足、软件配置不当及网络环境波动导致运行卡顿、服务中断等问题,影响用户体验,建议从资源优化、负载均衡及定期维护等方面入手,提升系统稳定性与响应效率。
当访客抱怨“服务器渣渣”时,究竟发生了什么?

作为网站运营者或技术管理者,你可能经常听到用户抱怨“服务器太卡”“页面打不开”“加载速度慢””,这些反馈的背后,往往指向一个核心问题:服务器性能不足,这不仅影响用户体验,还会直接导致流量流失、品牌口碑下降,甚至被搜索引擎降权,以下从技术、运营、优化三个维度深度解析“服务器渣渣”的根源与解决方案。
服务器性能不足的五大典型表现
- 响应时间过长
用户在浏览器输入网址后,页面加载超过3秒,50%的访客会选择离开(数据来源:Google核心性能指标),若服务器响应时间(TTFB)高于500ms,需警惕硬件或配置问题。 - 频繁宕机与502错误
服务器因CPU过载、内存耗尽或网络拥堵导致服务中断,出现“502 Bad Gateway”等错误代码,直接影响业务连续性。 - 数据库查询瓶颈
高并发场景下,数据库连接池耗尽、索引缺失或未优化的SQL语句会导致请求堆积,表现为页面长时间“转圈”。 - 流量突增时崩溃
促销活动或热点事件引发瞬时流量飙升,服务器因未配置弹性扩展(如自动扩容、CDN加速)而瘫痪。 - 安全破绽频发
未及时更新补丁、防火墙规则缺失或DDoS攻击防护不足,导致服务器频繁被载入或资源被反面占用。
为什么你的服务器成了“渣渣”?
硬件配置与业务需求不匹配
- 案例:某电商站点采用共享虚拟主机承载日均10万UV,导致CPU长期占用率超90%。
- 核心问题:
- 机械硬盘(HDD)无法支撑高IO读写需求。
- 单核CPU处理多线程任务时出现资源争抢。
- 内存不足触发频繁的Swap交换,拖慢整体速度。
软件环境配置失误
- 常见错误:
- Apache未启用Gzip压缩,静态资源传输效率低下。
- MySQL未调整innodb_buffer_pool_size,导致频繁磁盘读写。
- PHP-FPM进程数设置不合理,引发内存泄漏。
运维策略缺失
- 致命疏忽:
- 未部署监控系统(如Prometheus+Zabbix),无法实时预警CPU、内存、磁盘I/O异常。
- 日志文件未定期清理,占用大量存储空间。
- 备份机制不完善,遭遇攻击后无法快速恢复。
优化“渣服务器”的实战方案
硬件升级与架构重构
- 基础要求:
- 选择SSD固态硬盘,IOPS性能提升10倍以上。
- 采用多核CPU(如Intel Xeon E5系列)并启用超线程技术。
- 内存容量需满足“业务峰值需求×1.5”冗余(例如日常使用8GB,配置12GB)。
- 进阶方案:
- 分布式架构:将Web服务器、数据库、缓存(Redis/Memcached)分离部署。
- 负载均衡:通过Nginx或HAProxy分配请求至多台后端服务器。
软件层深度调优
- Web服务器优化:
# Nginx示例配置 gzip on; # 启用压缩 keepalive_timeout 30; # 减少TCP连接开销 worker_processes auto; # 自动分配工作进程
- 数据库调优:
- 为高频查询字段添加复合索引。
- 使用慢查询日志定位低效SQL语句。
- 读写分离:主库处理写操作,从库承担读请求。
运维自动化与监控
- 必装工具:
- 监控:Grafana+Prometheus(可视化资源使用趋势)。
- 日志管理:ELK Stack(集中分析错误日志)。
- 自动化部署:Ansible或Docker+Kubernetes。
- 紧急响应机制:
- 配置故障自动转移(Failover),切换至备份服务器。
- 设置带宽突发模式(Burst Mode)应对流量高峰。
长期预防:从“能用”到“好用”
- 压力测试与预案
使用JMeter或LoadRunner模拟高并发场景,确保服务器在2倍预期流量下稳定运行。 - 安全加固
- 定期更新系统补丁与SSL证书。
- 部署Web应用防火墙(WAF)拦截SQL注入、XSS攻击。
- 选择可靠服务商
- 优先考虑提供SLA(服务等级协议)的云服务商(如阿里云、AWS)。
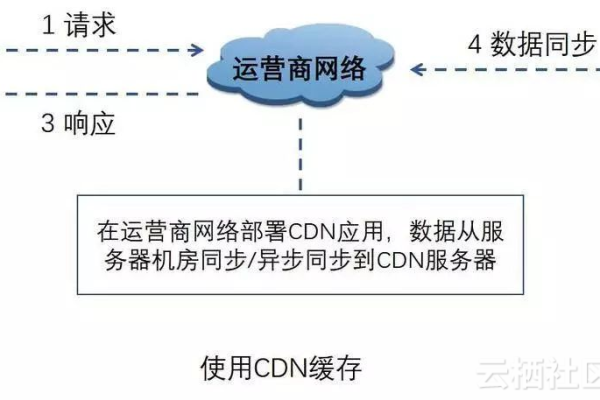
- 跨境业务需关注BGP多线接入与全球CDN节点覆盖。
用户自查清单
如果你的服务器出现以下症状,请立即行动:
页面加载时间 > 3秒
CPU使用率持续 > 70%
日均宕机次数 ≥ 1次
未启用HTTPS或HTTP/2协议
最近6个月未进行安全审计

引用说明
本文技术指标参考自Google Core Web Vitals、MySQL官方调优指南及《Web性能权威指南》(Ilya Grigorik著),运维方案借鉴AWS架构最佳实践与Linux基金会开源项目文档。







热门文章
-

云服务器在搭建实时报警平台中扮演什么角色?
2024-10-04 -

MySQL存储过程的高效使用与编写指南,如何优化C语言中的MySQL存储过程?
2025-03-08 -

为什么服务器在技术世界中如此受到青睐?
2024-10-08 -

配件网站模板_网站模板设置
2024-06-23 -

如何检查网络连接状态以确保设备已连接到互联网?
2025-03-01 -

如何轻松租用云服务器,关键步骤和技巧指南
2024-09-22 -

微信中拉黑某人后,其头像显示状态会有什么变化?
2024-11-12 -

是否必须购买云数据库以配合云服务器使用?
2024-09-20