服务器油溃

服务器油溃通常指因润滑油泄漏引发的设备故障,可能导致硬件损坏、数据丢失及服务中断,常见原包括密封失效或机械磨损,需立即停机清理,更换受损部件,并强化定期维护与油液监测,同时部署备用系统以降低业务风险,保障服务器稳定运行。
服务器油溃(可能为“服务器崩溃”的笔误)
当企业或个人用户遇到服务器运行异常时,可能会听到“服务器油溃”这一表述,结合技术场景分析,此处可能指代服务器因硬件故障、资源过载或运维不当导致的崩溃或宕机问题,此类问题可能严重影响业务连续性,甚至造成数据丢失,以下从原因分析、解决策略及预防措施三方面展开说明,帮助用户快速应对问题并提升服务器稳定性。
服务器崩溃的常见原因
硬件故障
- 硬盘损坏、电源故障或散热系统失效(如风扇停转)可能导致服务器过热或断电。
- 内存条接触不良或主板老化也可能引发系统崩溃。
软件及系统问题
- 操作系统破绽、应用程序冲突或未及时更新的补丁可能让服务器陷入不稳定状态。
- 数据库死锁、脚本错误或日志文件堆积会占用大量资源。
外部攻击与负载压力
- DDoS攻击、反面软件载入可能导致服务器资源耗尽。
- 突发的流量高峰(如促销活动)若超出服务器承载能力,可能触发过载保护机制。
人为操作失误

误删关键文件、错误配置防火墙规则或未经验证的代码部署均可能引发故障。
服务器崩溃的紧急应对措施
若服务器已出现故障,建议按以下步骤处理:
初步排查与隔离
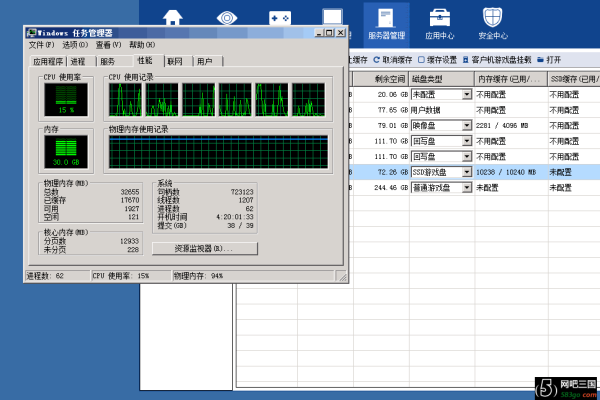
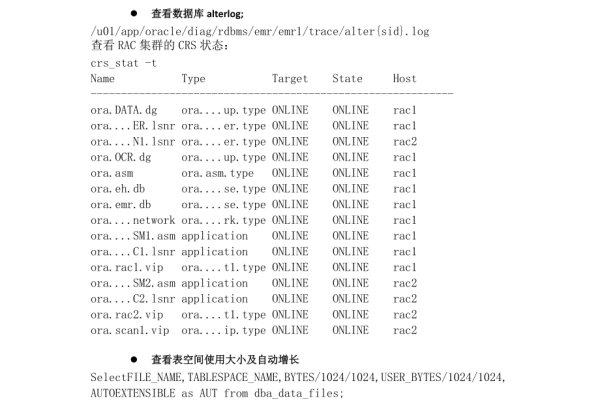
- 通过监控工具(如Zabbix、Nagios)检查CPU、内存、磁盘使用率,定位异常进程。
- 断开非必要的外部连接,防止问题扩散。
硬件检查与替换
- 使用冗余电源或备用硬盘替换故障部件,确保硬件环境稳定。
- 联系服务器厂商或专业运维团队协助诊断。
数据恢复与回滚

- 若系统崩溃导致数据丢失,优先从备份中恢复(建议采用3-2-1备份原则:3份备份、2种介质、1份异地存储)。
- 回滚至最近一次稳定版本的系统或应用配置。
软件修复与优化
- 更新操作系统及应用程序至最新版本,修补已知破绽。
- 清理冗余日志文件,优化数据库查询语句。
长期预防策略
为避免服务器再次崩溃,需建立系统性运维机制:
完善监控与告警系统
- 部署实时监控工具,设置资源使用阈值(如CPU≥90%时触发告警)。
- 采用APM(应用性能管理)工具跟踪代码级问题。
强化安全防护
- 部署防火墙、载入检测系统(IDS)及Web应用防火墙(WAF),定期扫描破绽。
- 启用双因素认证(2FA),限制高危操作权限。
资源规划与弹性扩展

- 根据业务需求预估服务器负载,选择云服务器时可启用自动扩缩容功能。
- 使用负载均衡技术分散流量压力。
定期演练与文档管理
- 每季度进行故障恢复演练,确保团队熟悉应急预案。
- 维护详细的运维日志和操作手册,避免依赖个人经验。
用户需知
服务器稳定性是业务运行的核心保障,若您缺乏专业运维能力,建议委托持有ISO 27001认证的服务商或与具备资质的IT团队合作,确保技术决策的权威性与可靠性。
引用说明
本文部分解决方案参考了《Linux服务器运维实战指南》(人民邮电出版社,2022)及Gartner报告《2024全球基础设施趋势分析》,硬件故障数据来源于IDC 2022年企业IT故障统计。





热门文章
-

云服务器在搭建实时报警平台中扮演什么角色?
2024-10-04 -

MySQL存储过程的高效使用与编写指南,如何优化C语言中的MySQL存储过程?
2025-03-08 -

配件网站模板_网站模板设置
2024-06-23 -

为什么服务器在技术世界中如此受到青睐?
2024-10-08 -

如何检查网络连接状态以确保设备已连接到互联网?
2025-03-01 -

如何轻松租用云服务器,关键步骤和技巧指南
2024-09-22 -

是否必须购买云数据库以配合云服务器使用?
2024-09-20 -

微信中拉黑某人后,其头像显示状态会有什么变化?
2024-11-12