上一篇
如何实现分布式存储的同步机制?
分布式存储同步通常通过复制或同步机制来实现,确保数据在多个节点间保持一致。这包括主从复制、多主复制和最终一致性等策略,使用如Apache Kafka、Google Spanner等技术实现高效、可靠的数据同步。
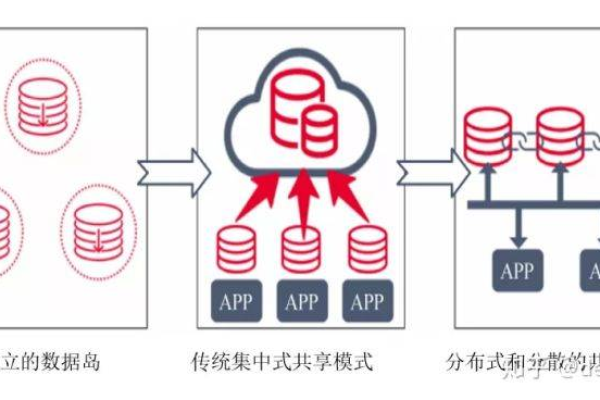
分布式存储同步是确保数据在多个位置、节点或设备上保持更新和一致的过程,这对于提高数据的可靠性、可用性和容错性至关重要,本文将详细探讨分布式存储的同步机制,包括其工作原理、关键技术以及面临的挑战和解决方案。

分布式存储同步的工作原理
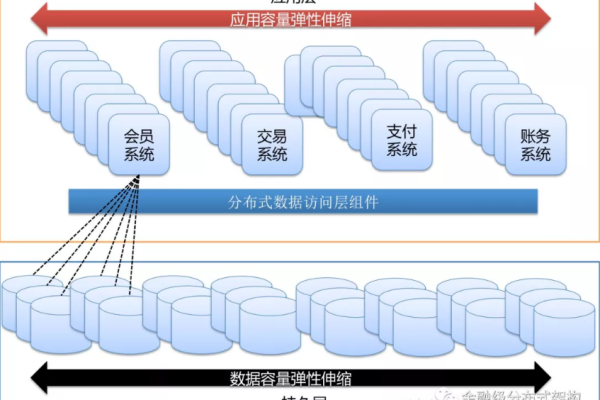
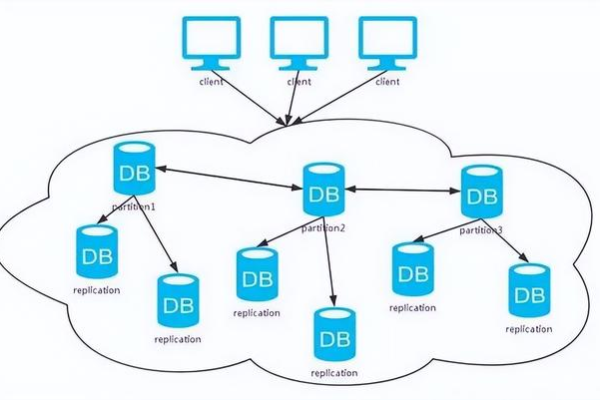
分布式存储系统通常由多个存储节点组成,这些节点通过网络连接并协同工作,以提供数据存储和访问服务,同步机制确保在这些节点上的数据保持一致,以下是几种常见的同步策略:
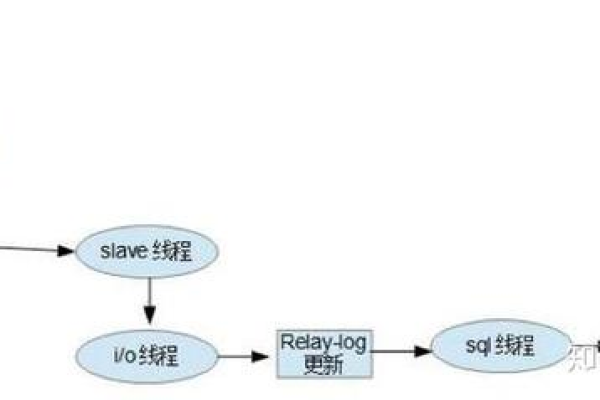
1、主从复制(Master-Slave Replication):
一个主节点负责处理所有写操作,然后将更改复制到一个或多个从节点。
优点:简单、易于实现。
缺点:单点故障,如果主节点宕机,系统将无法写入新数据。
2、多主复制(Multi-Master Replication):
每个节点都可以处理读写操作,并将更改传播到其他节点。
优点:高可用性,没有单点故障。
缺点:复杂的冲突解决机制。
3、基于日志的复制(Log-Based Replication):
通过记录和传输操作日志来同步数据。
优点:可以精确地重现数据变更历史。
缺点:日志管理复杂,可能需要额外的存储空间。
4、基于CRDTs(Convergent Replicated Data Types)的同步:
使用特殊的数据结构,如GCounters或ORSets,这些结构可以在不交换额外信息的情况下自然地合并状态。
优点:自动解决冲突,适用于高度动态的环境。
缺点:可能不适合所有类型的数据模型。
关键技术
一致性模型: 确保所有副本最终达到相同的状态,这可以是强一致性(如Paxos)、弱一致性(如最终一致性)或因果一致性。
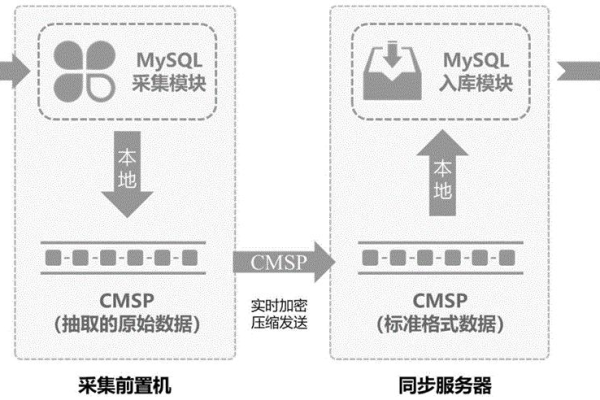
网络通信: 高效的网络协议和优化的数据传输对于减少延迟和提高吞吐量至关重要。
冲突解决: 在多主复制中,解决并发写入导致的冲突是一个重要问题,常用的方法包括版本向量、操作转换等。
面临的挑战与解决方案
网络分区: 当网络出现分割时,可能会导致数据不一致,解决方案包括使用Quorum技术或拜占庭容错算法。
性能开销: 同步操作可能会影响系统的响应时间和吞吐量,可以通过异步复制、批处理更新等方式来优化性能。
安全性: 保护在传输过程中的数据不被改动或泄露是另一个挑战,可以使用加密和认证机制来增强安全性。
相关问答FAQs
Q1: 如何选择合适的同步策略?
A1: 选择同步策略时应考虑应用场景的需求,如对一致性的要求、系统的可扩展性、容错能力和性能需求等,对于需要高可用性的系统,可以选择多主复制;而对于读密集型的系统,主从复制可能是更好的选择。
Q2: 如何处理分布式存储中的网络分区问题?
A2: 网络分区可以通过采用Quorum读取和写入策略来处理,确保只有在大多数副本可用时才进行操作,也可以使用拜占庭容错算法来容忍一定数量的节点故障。
小编有话说
随着云计算和大数据技术的发展,分布式存储系统变得越来越重要,有效的同步机制不仅能够提高数据的可靠性和可用性,还能增强系统的灵活性和可扩展性,我们可以期待更多创新的同步技术和策略,以应对不断变化的业务需求和技术挑战。
本站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本站,有问题联系侵删!
本文链接:http://www.xixizhuji.com/fuzhu/373936.html