
上一篇
如何利用 Chrome 图像识别 API 提升应用功能?
Chrome图像识别API
Chrome浏览器中的图像识别功能主要通过Google Lens实现,这是一个强大的图像识别工具,虽然目前Google Lens在移动端已经非常成熟,但在桌面端的应用也在不断扩展和改进。

功能与应用场景
1、图像搜索:用户可以通过右键点击图片并选择“用Google Lens搜索图片”来查找相似或相关的图片,这对于寻找特定物体、场景或艺术作品非常有用。
2、来源识别:Google Lens可以帮助用户找到图片的来源,例如某张图片最初出现在哪里,或者是否有其他网站使用了这张图片。
3、文字识别与翻译:除了图像识别外,Google Lens还可以识别图片中的文字并进行翻译,这对于处理多语言文档或从图片中提取信息非常有用。
4、条形码与二维码扫描:用户可以扫描图片中的条形码或二维码以获取相关信息,如产品详情或链接。
5、面部检测:Chrome Canary(M57)版本中引入了Shape Detection API,可以用于检测图像中的面部区域,这为开发者提供了在Web应用中集成面部检测功能的可能性。
技术实现与渐进增强
底层硬件支持:为了提高图像识别的性能和准确性,Chrome可能会利用底层硬件的支持,如GPU加速等。
渐进增强策略:Chrome采用渐进增强的策略,即在不影响低版本Chrome用户体验的情况下,逐步引入新功能,这意味着即使用户的Chrome版本较低,他们仍然可以使用基本的图像识别功能。
Web Assembly与原生库:为了进一步提高性能,Chrome可能会利用Web Assembly技术将原生库(如OpenCV)集成到浏览器中,从而实现更高效的图像识别。
表格对比
| 特性 | Google Lens(桌面版) | Shape Detection API |
| 功能 | 图像搜索、来源识别、文字识别与翻译、条形码/二维码扫描 | 面部检测 |
| 应用场景 | 寻找特定物体、场景或艺术作品;查找图片来源;处理多语言文档;扫描条形码/二维码 | Web应用中集成面部检测功能,如局部图片剪裁、自动优化面部识别等 |
| 技术实现 | 利用Google的图像识别技术,可能结合底层硬件支持 | 基于用户设备的一些基础硬件功能创建标准接口,可利用Web Assembly集成原生库 |
| 渐进增强 | 是,不影响低版本Chrome用户体验 | 是,提供纯JS方案、服务器端处理及Web Assembly高性能实现 |
常见问题解答
Q1: Google Lens在桌面端的使用是否需要特殊设置?<br>
A1: 不需要特殊设置,只需在Chrome浏览器中右键点击图片并选择“用Google Lens搜索图片”即可。
Q2: Shape Detection API是否支持所有平台?<br>
A2: 目前Shape Detection API主要支持Android的Chrome Canary,桌面端的支持正在开发中。
Q3: 如何在我的Web应用中集成面部检测功能?<br>
A3: 你可以使用Shape Detection API,通过调用faceDetector.detect(image)方法来实现面部检测,并将检测结果绘制在图像上。
Chrome图像识别API(主要是Google Lens)为用户提供了强大的图像识别功能,包括图像搜索、来源识别、文字识别与翻译、条形码/二维码扫描以及面部检测等,这些功能不仅提高了用户的浏览体验,也为开发者提供了丰富的集成选项,随着技术的不断发展和进步,我们可以期待Chrome在未来会提供更多创新的图像识别功能。
小伙伴们,上文介绍了“chrome 图像识别 api”的内容,你了解清楚吗?希望对你有所帮助,任何问题可以给我留言,让我们下期再见吧。
本站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本站,有问题联系侵删!
本文链接:http://www.xixizhuji.com/fuzhu/373196.html
相关文章
-
Chrome 如何导出证书?,详解 Chrome 浏览器证书导出步骤与注意事项,,Chrome 浏览器简介,证书重要性,导出证书前准备,确认网站使用 HTTPS,打开开发者工具,导出证书步骤,查看证书信息,复制证书到文件,导入证书方法,打开Chrome设置页面,选择管理证书,完成证书导入,常见问题解答,无法查看证书信息,导出证书失败,导入证书无效,归纳与未来趋势,Chrome 安全功能发展趋势,用户需关注网络安全措施
-
Chrome 如何导出证书?,详解 Chrome 浏览器证书导出步骤与注意事项,,Chrome 浏览器简介,证书重要性,导出证书前准备,确认网站使用 HTTPS,打开开发者工具,导出证书步骤,查看证书信息,复制证书到文件,导入证书方法,打开Chrome设置页面,选择管理证书,完成证书导入,常见问题解答,无法查看证书信息,导出证书失败,导入证书无效,归纳与未来趋势,Chrome 安全功能发展趋势,用户需关注网络安全措施
-
如何利用面部图像识别技术提升图像识别的准确性和效率?
-

Chrome浏览器(chrome浏览器安卓版下载)(chrome浏览器官方下载 安卓)
-

chrome高级设置,GoogleChromeIPV6设置是哪个,chrome浏览器高级设置
-
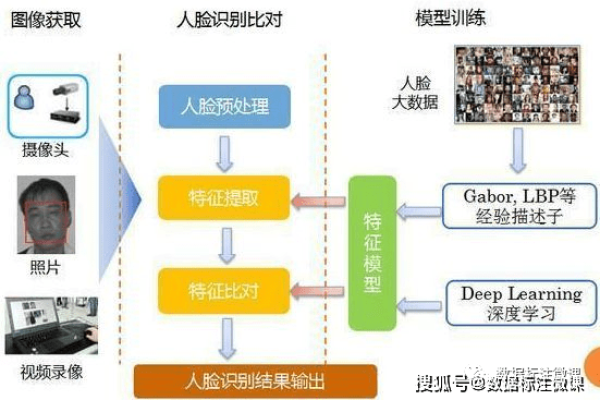
如何通过目标图像识别技术提升图像识别的准确性?
-
皮肤图像识别_图像识别
-
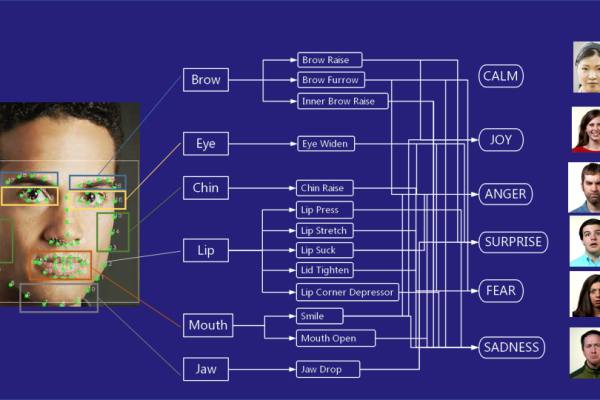
动态图像识别_图像识别








