上一篇
分布式存储三副本技术究竟备份了几份数据?
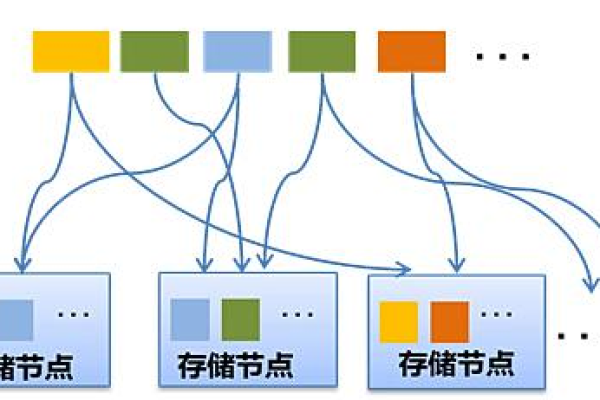
分布式存储三副本是备份三份,即每个数据块在三个不同的节点上各存储一份。
分布式存储三副本是备份几份
在现代数据存储和管理中,分布式存储系统扮演着关键角色,为了确保数据的高可用性和可靠性,许多分布式存储系统采用多副本策略。“三副本”是一种常见的数据冗余机制,什么是三副本?它具体是如何工作的?本文将详细探讨这些问题,并解答一些常见问题。

一、什么是三副本?
三副本(Replication)是指将同一份数据复制成三份,并将其分别存储在不同的物理位置上,这样即使其中某一份或两份数据出现故障,其他副本仍然可以继续提供服务,从而保证数据的高可用性和容错性。
二、三副本的工作机制
1、数据写入:当客户端向分布式存储系统写入数据时,系统会将数据复制成三份,并将它们分别存储在三个不同的节点上,这些节点通常分布在不同的数据中心或机架上,以减少单点故障的风险。
2、数据读取:当客户端请求读取数据时,系统会从三个副本中选择一个进行读取,通常情况下,会选择响应时间最短或负载最轻的副本来提供服务,以提高性能和效率。
3、故障恢复:如果某个节点发生故障,系统会自动从其他副本中恢复丢失的数据,并将新数据同步到新的节点上,以确保数据的一致性和完整性。
4、数据更新:当数据需要更新时,系统会同时更新所有副本,以保证数据的一致性,如果更新过程中某个副本失败,系统会重新尝试更新,直到所有副本都成功更新为止。
三、三副本的优势
1、高可用性:通过将数据复制成三份并分布在不同的位置,系统可以在单个或多个节点故障的情况下继续提供服务。
2、容错性:即使两个副本同时失效,第三个副本仍然可以保证数据的可用性。
3、性能优化:通过选择响应时间最短或负载最轻的副本进行读写操作,可以提高系统的整体性能。
4、数据一致性:所有副本都会同步更新,确保在任何时刻数据的一致性。
四、三副本的应用场景
1、大规模分布式存储系统:如Hadoop HDFS、Amazon S3等,这些系统需要处理海量数据,并且对数据的可靠性和可用性要求极高。
2、数据库系统:如Cassandra、MongoDB等,这些系统需要支持高并发访问和快速的数据恢复。
3、云存储服务:如Google Cloud Storage、Microsoft Azure Storage等,这些服务需要提供高可用性和可扩展性的存储解决方案。
五、三副本的实现细节
1、副本放置策略:系统会根据网络拓扑和数据中心布局,将副本放置在不同的位置,以最大化容错能力和性能。
2、一致性模型:系统可以选择强一致性或最终一致性模型,根据应用需求来决定数据同步的频率和方式。
3、心跳检测:系统会定期发送心跳信号来检测各个节点的状态,如果某个节点长时间未响应,系统会认为该节点已失效,并启动故障恢复流程。
六、FAQs
Q1:为什么选择三副本而不是两副本或四副本?
A1:选择三副本是为了在保证数据高可用性和容错性的同时,尽量减少存储资源的消耗,两副本虽然可以减少存储成本,但其容错能力较弱;而四副本虽然容错能力更强,但存储成本较高,综合考虑性能和成本,三副本是一个较为合理的选择。
Q2:三副本是否适用于所有场景?
A2:不一定,三副本适用于对数据可用性和可靠性要求较高的场景,但在一些对性能要求极高的场景下,过多的副本可能会影响系统的响应速度,在选择副本数量时,需要根据具体的应用场景和需求进行权衡。
七、小编有话说
分布式存储系统中的三副本机制是一种有效的数据冗余策略,能够在保证数据高可用性和容错性的同时,提高系统的性能和可靠性,不同的应用场景对数据的要求各不相同,因此在实际应用中需要根据具体需求选择合适的副本数量和放置策略,希望通过本文的介绍,读者能够对分布式存储系统中的三副本机制有一个全面的了解。
本站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本站,有问题联系侵删!
本文链接:https://www.xixizhuji.com/fuzhu/372286.html