cdn 加载

CDN 加载的原理与过程
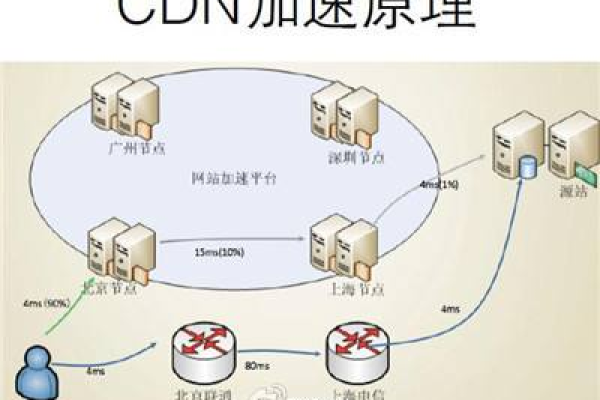
CDN(内容分发网络)的工作原理是通过在全球各地部署服务器节点,将网站的内容缓存到离用户最近的节点上,当用户请求网站内容时,CDN会自动选择距离用户最近的节点服务器来提供内容,从而减少延迟和提高访问速度,以下是其详细的加载过程:
1、域名解析:用户在浏览器中输入要访问的网站域名后,本地 DNS 服务器会先将域名解析的请求发送至根 DNS 服务器,根 DNS 服务器接受请求后,会将域名解析权交给顶级域名服务器,顶级域名服务器再将请求分配到相应的权威域名服务器,权威域名服务器最终将域名解析结果反馈给根 DNS 服务器,根 DNS 服务器再将其传递给本地 DNS 服务器,本地 DNS 服务器将结果返还给用户,用户获得解析后的 IP 地址。
2、发起请求:用户的设备向获取到的 IP 地址(即 CDN 的全局负载均衡设备 IP 地址)发起内容 URL 访问请求。
3、负载均衡:CDN 的全局负载均衡设备根据用户 IP 地址、请求的内容 URL 中的携带内容名称以及用户请求的用户位置等信息,选择一台用户所属区域的区域负载均衡设备,告诉用户向这台设备发起请求。
4、缓存处理:用户向所属区域的负载均衡设备发起内容 URL 访问请求,这台设备会选择一台用户所属区域的缓存服务器,让用户向这台缓存服务器发起请求,缓存服务器响应用户的请求,将用户所需内容传送到用户终端,如果缓存服务器上没有用户想要的内容,而缓存服务器又无法从源存储空间服务器获取到用户所需的内容时,缓存服务器就会向源存储空间服务器回溯。
5、源站处理:源站服务器响应缓存服务器的请求,将内容发给缓存服务器,缓存服务器根据用户自定义缓存策略,判断要不要把源站发送的内容缓存到缓存服务器上。
6、内容分发:如果缓存服务器已缓存用户所需内容,则直接将内容传送至用户终端;如果未缓存,则缓存服务器需要向源站服务器请求内容,直到获取并缓存后再传送至用户终端。
常见问题及解答
1、什么是 CDN?

CDN 的全称是 Content Delivery Network,即内容分发网络,它是利用分布式服务器技术,将网站的内容发布到不同区域的目标服务器上,以实现快速、稳定和高效的内容传输。
2、CDN 的主要作用是什么?
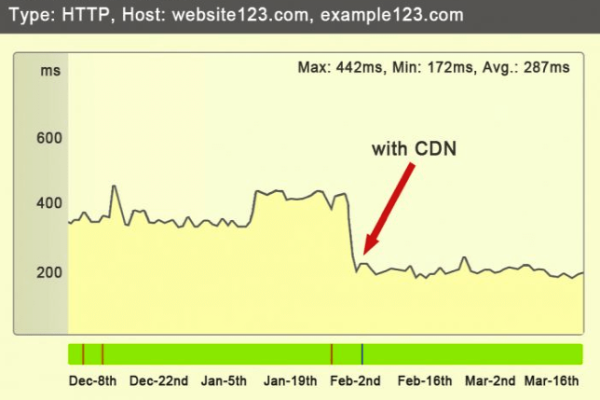
加速网站访问:通过将网站内容缓存到离用户最近的节点服务器上,实现就近访问,减少内容传输的距离和网络延迟,大幅提高网站的访问速度,加快加载,提升用户体验。
减轻源服务器压力:CDN 可以缓存大量的静态资源,如图片、CSS、JavaScript 等,减少了对源服务器的访问次数,从而减轻了源服务器的负载压力,节约了网络带宽的使用,提高了整体的网络效率。
提高网站的可用性和稳定性:由于 CDN 是分布式部署的,即使某个节点服务器出现故障,也不会影响其他节点的正常服务,从而提高了网站的可用性和稳定性,减少了中断的风险。
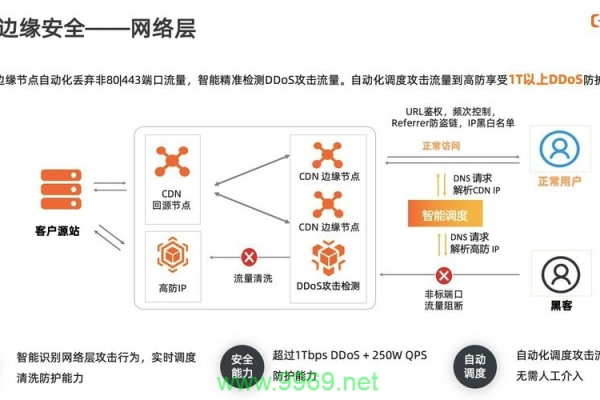
抵御网络攻击:CDN 可以通过分散流量的方式,有效地抵御 DDoS 攻击等网络攻击,保护网站的安全。

3、如何选择合适的 CDN 服务提供商?
考虑节点分布:选择在全球范围内拥有广泛节点分布的 CDN 服务提供商,尤其是在目标用户群体集中的地区拥有足够多的节点,以确保能够快速响应用户的请求。
评估性能和服务质量:关注 CDN 服务提供商的性能指标,如响应时间、吞吐量等,同时了解其技术支持、故障恢复能力等方面的服务质量,以确保在出现问题时能够及时解决。
关注安全性:确保 CDN 服务提供商具备强大的安全防护机制,如 DDoS 防护、WAF(Web 应用防火墙)等,以保障网站的数据安全。
了解价格和服务条款:不同的 CDN 服务提供商在价格和服务条款上可能会有所不同,需要根据自身的预算和需求进行综合考虑。
4、CDN 加载速度慢的可能原因及解决方法?

缓存未命中:如果用户请求的资源在 CDN 节点上没有缓存,就需要从源服务器获取,这会增加加载时间,可以通过优化缓存策略,提高缓存命中率来解决。
源站问题:源站服务器的性能或网络状况不佳,也会影响 CDN 的加载速度,需要检查源站服务器的配置和运行状态,确保其能够稳定地提供服务。
网络拥塞:CDN 节点之间的网络出现拥塞,数据传输就会变慢,可以通过优化网络架构、增加带宽等方式来缓解网络拥塞。
配置错误:CDN 的配置参数不正确,也可能导致加载速度慢,需要仔细检查 CDN 的配置设置,确保其符合最佳实践。





热门文章
-

云服务器在搭建实时报警平台中扮演什么角色?
2024-10-04 -

MySQL存储过程的高效使用与编写指南,如何优化C语言中的MySQL存储过程?
2025-03-08 -

配件网站模板_网站模板设置
2024-06-23 -

为什么服务器在技术世界中如此受到青睐?
2024-10-08 -

如何检查网络连接状态以确保设备已连接到互联网?
2025-03-01 -

如何轻松租用云服务器,关键步骤和技巧指南
2024-09-22 -

是否必须购买云数据库以配合云服务器使用?
2024-09-20 -

微信中拉黑某人后,其头像显示状态会有什么变化?
2024-11-12