上一篇
如何精准识别图像中的文字并从图片中提取出来?
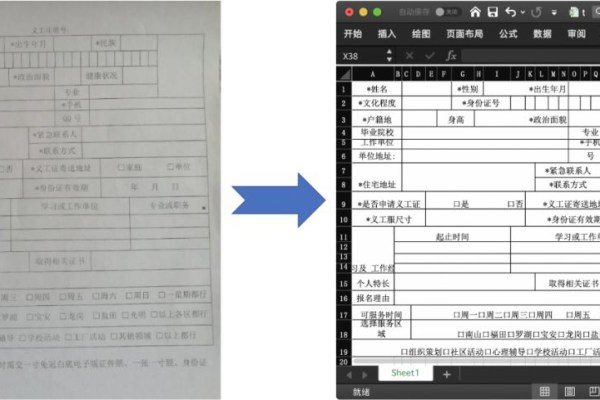
要精准识别图像中的文字,可使用OCR(光学字符识别)技术。通过算法分析图像像素,提取并转换文字信息,确保高准确度。
在当今信息爆炸的时代,从图片中提取文字的需求日益增长,无论是为了文档数字化、数据录入还是内容分析,图像文字识别技术都扮演着至关重要的角色,精准识别图像中的文字不仅能够提高工作效率,还能减少人为错误,为各行各业带来便利,本文将详细介绍如何实现从图片中提取文字的精准识别,包括技术原理、常用工具、操作步骤以及常见问题解答。

一、技术原理
图像文字识别(Optical Character Recognition, OCR)是一种通过扫描文档、图像或文本页面等物理对象,将其转换为机器编码文本的过程,OCR技术的核心在于训练深度学习模型,使其能够理解和识别不同字体、大小和格式的字符,这些模型通常基于卷积神经网络(CNN),通过大量的标注数据进行训练,以学习字符的特征表示。
二、常用工具
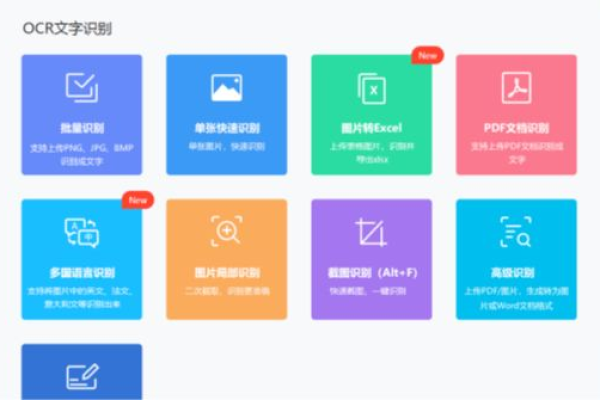
Tesseract OCR:一个开源的OCR引擎,支持多种操作系统和编程语言,具有高度可定制性。
Google Cloud Vision API:提供强大的图像分析服务,包括文字检测和识别,适用于大规模应用。
Microsoft Azure Computer Vision API:同样提供文字识别功能,集成了微软的先进机器学习算法。
ABBYY FineReader:一款商业软件,以其高准确率和强大的后处理能力著称。
三、操作步骤
1、图像预处理:调整图像大小、亮度和对比度,以提高文字识别的准确性。
2、文字检测:使用OCR工具定位图像中的文字区域。
3、特征提取:从检测到的文字区域中提取特征,供后续识别使用。
4、文字识别:利用训练好的模型对提取的特征进行解码,输出识别的文字。
5、后处理:对识别结果进行校正和格式化,如去除多余的空格、标点符号等。
四、表格示例
| 步骤 | 描述 | 工具/技术 |
| 图像预处理 | 调整图像大小、亮度和对比度 | OpenCV, PIL |
| 文字检测 | 定位图像中的文字区域 | Tesseract, Google Cloud Vision |
| 特征提取 | 从文字区域中提取特征 | CNN, SIFT |
| 文字识别 | 对特征进行解码 | Tesseract, ABBYY FineReader |
| 后处理 | 校正和格式化识别结果 | NLTK, 正则表达式 |
五、相关问答FAQs
Q1: OCR技术的准确率如何提高?
A1: 提高OCR准确率的方法包括:优化图像质量,确保文字清晰;选择合适的OCR工具和算法;对特定领域的文本进行定制化训练;以及使用后处理技术校正识别结果。
Q2: OCR技术在哪些领域有广泛应用?
A2: OCR技术广泛应用于文档数字化、票据处理、身份证件识别、书籍和文章转录、车牌号识别等多个领域,极大地提高了数据处理的效率和准确性。
六、小编有话说
随着人工智能技术的不断发展,OCR技术也在不断进步,其应用场景越来越广泛,要实现从图片中提取文字的精准识别,仍然需要不断优化算法、提升模型性能,并结合实际应用场景进行定制化开发,希望本文能为大家在OCR技术的应用和研究上提供一些有益的参考和启示。
本站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本站,有问题联系侵删!
本文链接:http://www.xixizhuji.com/fuzhu/367121.html