上一篇
如何实现在MySQL中随机抽取5条数据并应用到随机森林回归模型中?
MySQL中随机取5条数据可使用 ORDER BY RAND() LIMIT 5,而随机森林回归是一种集成学习方法。
在数据库管理和数据分析领域,MySQL和随机森林回归都是非常强大的工具,下面将详细介绍如何在MySQL中随机取5条数据,以及随机森林回归的基本原理和应用。

MySQL随机取5条数据
在MySQL中从一个大表中随机取出几条数据是一个常见需求,但直接使用ORDER BY RAND()方法在大表上效率低下,以下是几种高效的方法来实现这一需求:
1、基于最大值和最小值的方法:
SELECT * FROM table_name WHERE RAND() < (SELECT (MAX(id) MIN(id)) / 5 FROM table_name) LIMIT 5;
这种方法通过计算表中ID的最大值和最小值,然后生成一个随机数范围来选择数据,效率较高。
2、基于JOIN的方法:
SELECT t1.* FROM table_name AS t1 JOIN (SELECT id FROM table_name ORDER BY RAND() LIMIT 5) AS t2 ON t1.id = t2.id;
这种方法首先随机选择5个ID,然后再与原表进行连接,获取对应的记录。
3、基于子查询的方法:
SELECT * FROM table_name WHERE id >= (SELECT FLOOR(RAND() * (SELECT MAX(id) FROM table_name))) ORDER BY id LIMIT 5;
这种方法通过随机生成一个ID,然后在大于该ID的记录中选择前5条,效率也较高。
随机森林回归
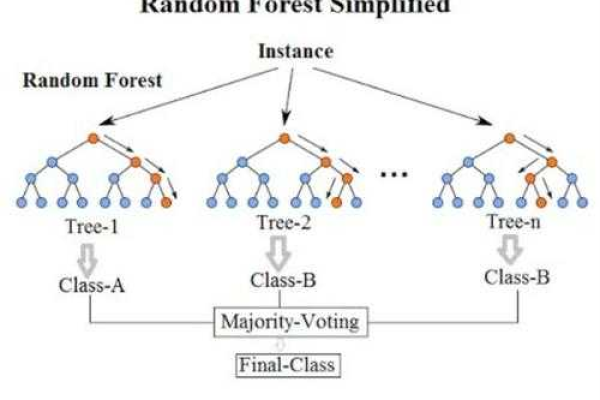
随机森林回归是一种基于集成学习的机器学习算法,通过构建多个决策树并将它们的预测结果进行平均或加权平均来进行回归任务,下面是其详细步骤:
原理
随机森林回归通过以下步骤实现:
1、随机选择样本:从原始训练集中随机选择一部分样本,构成一个子样本集,每棵决策树都在不同的子样本集上进行训练。
2、随机选择特征:对于每个决策树的每个节点,在选择最佳划分特征时,只考虑随机选择的一部分特征,这样可以防止某些特征对整个模型的影响过大。
3、构建决策树:在每个子样本集上使用某种决策树算法(如CART算法)构建一棵决策树,决策树的生长过程中,通常采用递归地选择最佳划分特征,将数据集划分为不纯度最小的子集。
4、集成预测:对于新的输入样本,通过将多棵决策树的预测结果进行平均或加权平均,从而得到最终的回归结果。
示例代码(Python)
以下是使用Scikit-learn库中的RandomForestRegressor类构建和训练一个随机森林回归模型的示例代码:
导入必要的库
import pandas as pd
import numpy as np
from sklearn.ensemble import RandomForestRegressor
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error, mean_absolute_error, r2_score
读取数据集
data = pd.read_csv('data.csv') # 假设数据集保存在名为data.csv的CSV文件中
划分特征和目标变量
X = data.drop('target', axis=1)
y = data['target']
划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
构建随机森林回归模型
rf = RandomForestRegressor(n_estimators=100, random_state=42) # 设置决策树的数量为100
训练模型
rf.fit(X_train, y_train)
预测结果
y_pred = rf.predict(X_test)
模型评估
mse = mean_squared_error(y_test, y_pred)
mae = mean_absolute_error(y_test, y_pred)
r2 = r2_score(y_test, y_pred)
print('Mean Squared Error (MSE):', mse)
print('Mean Absolute Error (MAE):', mae)
print('R-squared (R2):', r2)常见问题及解答(FAQs)
Q1: 为什么在MySQL中使用ORDER BY RAND()方法效率低下?
A1:ORDER BY RAND()方法需要为每一行生成一个随机数并进行排序,这在大表上会非常耗时,导致查询效率低下。
Q2: 如何选择合适的参数来调优随机森林回归模型?
A2: 可以通过交叉验证等方法选择合适的参数,例如增加或减少决策树的数量、调整特征选择的方式、调整决策树的生长方式等,从而提高模型的性能。
小编有话说
在处理大规模数据时,选择合适的方法和工具至关重要,MySQL中的随机取数操作可以通过多种高效的SQL语句实现,而随机森林回归则是一种强大的机器学习算法,适用于各种回归任务,希望本文能为您在实际工作中提供帮助,让您能够更高效地处理数据并构建出性能优异的模型,如果您有任何问题或建议,欢迎留言讨论!
本站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本站,有问题联系侵删!
本文链接:http://www.xixizhuji.com/fuzhu/366422.html