服务器收集日志原理

服务器通过代理或内置服务实时采集应用、系统等日志数据,经格式化后通过网络协议传输至中央存储系统,进行统一索引、分析和存储,并支持实时监控、查询及异常告警,实现日志全生命周期管理。
日志的生成与内容
服务器日志由操作系统、应用程序或中间件自动生成,通常包含以下核心信息:
- 时间戳:记录事件发生的精确时间(如
2024-10-05T14:23:01+08:00)。 - 事件类型:例如用户登录、API请求、错误告警或系统资源告急。
- 来源标识:包括客户端IP地址、用户代理(User Agent)、设备类型等。
- 操作详情:如访问的URL路径、HTTP状态码(200/404/500)、响应时间。
- 资源状态:CPU使用率、内存占用、磁盘I/O等性能指标。
示例日志片段:

168.1.100 - - [05/Oct/2024:14:23:01 +0800] "GET /api/data HTTP/1.1" 200 1534 "https://example.com" "Mozilla/5.0 (Windows NT 10.0; Win64; x64)"日志收集的核心流程
日志采集
- 被动监听模式:通过Syslog协议(RFC 5424标准)实时接收日志流,适用于Linux/Unix系统。
- 主动抓取模式:使用Filebeat、Fluentd等工具定期扫描日志文件(如Nginx的
access.log),适合高吞吐场景。 - 应用级集成:在代码中嵌入Log4j、Winston等日志框架,实现结构化输出(JSON格式)。
日志传输
- 加密通道:通过TLS/SSL加密的TCP协议传输,防止数据泄露。
- 缓冲队列:引入Kafka或RabbitMQ作为消息中间件,应对流量高峰。
- 压缩优化:采用GZIP或Snappy算法减少带宽占用。
日志处理
- 解析与标准化:使用Grok正则表达式提取字段,例如将原始文本转化为:
{ "client_ip": "192.168.1.100", "method": "GET", "path": "/api/data", "status_code": 200 } - 富化增强:通过IP地址关联地理位置,或结合用户ID补充账户信息。
- 异常检测:基于规则引擎(如Elasticsearch Watcher)识别错误率突增、SQL注入攻击等模式。
存储与检索技术
存储架构
冷热分层:

- 热存储:Elasticsearch实时索引,支持秒级查询。
- 温存储:HDFS分布式文件系统,存放近30天数据。
- 冷存储:AWS S3 Glacier,归档历史日志。
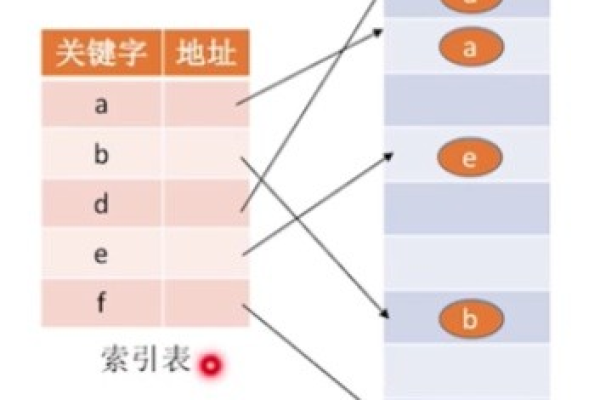
索引优化:
- 按时间分片(如每日一个索引)提升查询效率。
- 对高频查询字段(如
status_code)建立倒排索引。
检索方案
- 全文搜索:通过Kibana输入
status_code:500 AND path:/payment定位支付失败请求。 - 聚合分析:统计不同API端点的95%响应时间,生成性能报告。
- 机器学习:使用Elastic ML自动检测流量异常波动。
安全与合规要求
- 数据脱敏:对敏感字段(如身份证号、Cookie)进行掩码处理()。
- 访问控制:基于RBAC模型限制工程师的日志查看范围。
- 合规留存:
- 符合GDPR:用户行为日志保留不超过6个月。
- 满足《网络安全法》:操作审计日志至少留存180天。
典型应用场景
- 故障排查:通过日志追溯服务雪崩的触发点(如某个微服务超时引发连锁反应)。
- 安全审计:识别暴力破解行为(如同一IP在1分钟内尝试50次登录)。
- 业务洞察:分析用户访问路径,优化页面转化率。
引用说明
本文技术细节参考以下权威资料:

- IETF Syslog协议标准(RFC 5424)
- Elastic官方文档《Elasticsearch: The Definitive Guide》
- Nginx核心开发者提供的日志模块设计指南
- 《企业网络安全日志管理规范》(GB/T 35282-2017)


热门文章
-

云服务器在搭建实时报警平台中扮演什么角色?
2024-10-04 -

MySQL存储过程的高效使用与编写指南,如何优化C语言中的MySQL存储过程?
2025-03-08 -

为什么服务器在技术世界中如此受到青睐?
2024-10-08 -

配件网站模板_网站模板设置
2024-06-23 -

如何检查网络连接状态以确保设备已连接到互联网?
2025-03-01 -

如何轻松租用云服务器,关键步骤和技巧指南
2024-09-22 -

是否必须购买云数据库以配合云服务器使用?
2024-09-20 -

CFTPSSL证书是什么?它如何提升文件传输的安全性?
2024-12-15