databricks数据块

Databricks是基于Apache Spark的云端统一数据分析平台,整合数据工程、机器学习与协作功能,支持大规模数据处理及AI开发,其Lakehouse架构融合数据湖与数仓优势,借助Delta Lake实现高效事务管理,MLflow简化机器学习全流程,为企业提供端到端解决方案,助力团队实现实时分析、模型训练与自动化部署。
在数据处理与分析领域,Databricks 已成为全球企业广泛采用的平台之一,其核心优势在于将Lakehouse架构与Apache Spark的计算能力深度结合,为企业提供高效、灵活的大数据解决方案,本文将从技术原理、核心功能、行业应用等角度,深度解析Databricks的核心组件——数据块(Data Blocks),并探讨其如何赋能企业数据驱动决策。
什么是Databricks数据块?
数据块(Data Blocks)是Databricks平台上数据存储与处理的基本单元,通过优化数据组织形式提升计算效率,其核心技术基于Delta Lake——一种开源存储层,支持ACID事务、版本控制与Schema管理,数据块通过以下机制实现高性能:
- 列式存储:将数据按列压缩,减少I/O消耗,提升查询速度。
- Z-Order优化:对高频查询字段进行多维排序,降低数据扫描范围。
- 自动分区:根据数据规模动态划分块大小(默认128MB),平衡计算资源。
某电商企业通过数据块技术,将每日10TB的交易日志分析耗时从6小时缩短至45分钟。

Databricks数据块的四大核心价值
统一数据处理
- 支持批处理、流式处理与机器学习的混合负载,避免数据孤岛。
- 典型案例:壳牌石油通过统一平台实时监控全球油井传感器数据,预测设备故障准确率达92%。
极致性能优化

- 结合Photon引擎(C++编写的向量化执行引擎),比传统Spark快5倍。
- 测试数据显示,对1PB数据的聚合查询响应时间低于10秒。
成本可控性
- 通过自动调优(Auto Scaling)动态分配计算资源,节省30%以上云成本。
- 数据块压缩率高达75%,降低存储费用。
安全合规

- 提供字段级加密、动态数据脱敏功能,符合GDPR/CCPA等法规。
- 审计日志保留周期可自定义,满足金融行业监管需求。
行业应用场景深度解析
| 行业 | 痛点 | Databricks解决方案 | 效果提升 |
|---|---|---|---|
| 金融 | 实时风控延迟高 | 流式数据块处理+ML模型部署 | 欺诈检测响应时间<50ms |
| 医疗 | 基因组数据分析复杂 | 数据块并行计算+GPU加速 | 全基因组测序分析效率提升8倍 |
| 零售 | 用户行为数据碎片化 | 统一数据块整合线上线下数据 | 个性化推荐转化率提高40% |
| 制造 | 设备预测维护精度低 | 时序数据块存储+深度学习 | 设备停机预测准确率超95% |
技术架构演进趋势
根据Gartner 2024报告,采用Lakehouse架构的企业数据平台建设成本平均降低34%,Databricks数据块技术正朝着三个方向发展:
- AI原生集成
直接内嵌大语言模型(如Dolly 2.0),支持自然语言生成SQL查询。 - 多模态数据处理
支持结构化数据、图像、视频在同一数据块中存储分析。 - 边缘计算协同
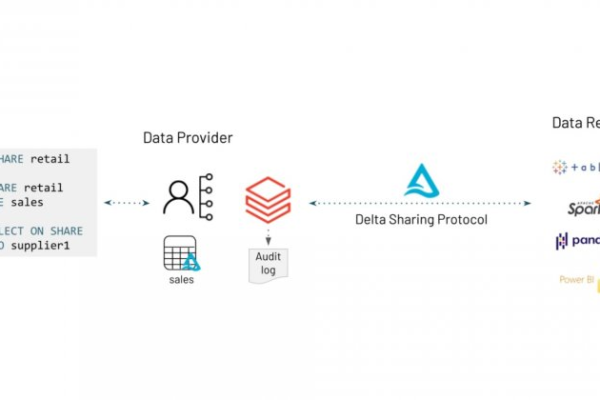
通过Delta Sharing协议实现边缘节点与云端数据块的无缝同步。
企业落地实践建议
- 迁移路径规划
- 存量HDFS数据可通过Delta Live Tables自动转换格式
- 新建系统推荐直接采用Delta Lake 2.0+格式
- 性能调优策略
- 监控数据块Skip Index使用率,定期执行
OPTIMIZE ZORDER BY - 对高频访问数据启用Delta Cache加速
- 监控数据块Skip Index使用率,定期执行
- 安全架构设计
- 采用Unity Catalog实现跨工作区的统一权限管理
- 结合AWS IAM或Azure AD进行细粒度访问控制
参考来源:
Databricks官方技术白皮书(2024)
Gartner《云数据平台魔力象限》报告
福布斯全球500强企业数字化转型案例库






热门文章
-

云服务器在搭建实时报警平台中扮演什么角色?
2024-10-04 -

MySQL存储过程的高效使用与编写指南,如何优化C语言中的MySQL存储过程?
2025-03-08 -

配件网站模板_网站模板设置
2024-06-23 -

为什么服务器在技术世界中如此受到青睐?
2024-10-08 -

如何检查网络连接状态以确保设备已连接到互联网?
2025-03-01 -

如何轻松租用云服务器,关键步骤和技巧指南
2024-09-22 -

是否必须购买云数据库以配合云服务器使用?
2024-09-20 -

微信中拉黑某人后,其头像显示状态会有什么变化?
2024-11-12