服务器操作系统应急预案

服务器操作系统应急预案旨在确保系统突发故障时快速恢复运行,核心内容包括风险评估、备份策略、实时监控及多级故障响应机制,明确系统崩溃、数据丢失等场景的处置流程,建立高可用架构与冗余备份,制定团队分工与紧急联络清单,定期演练优化方案,最大限度降低停机损失,保障业务连续性与数据安全。
为什么需要服务器操作系统应急预案?
服务器是企业数字资产的核心载体,操作系统(如Windows Server、Linux等)的稳定性直接影响业务连续性,据统计,超过40%的企业因未制定应急预案导致故障恢复时间超过24小时(来源:Gartner),造成直接经济损失与声誉风险,应急预案的目标是最小化停机时间、保障数据完整性、降低人为误操作风险。
应急预案的核心要素
风险评估与场景分类
- 硬件故障(硬盘损坏、电源故障)
- 软件故障(系统崩溃、补丁冲突)
- 网络攻击(DDoS、勒索干扰)
- 自然灾害(断电、火灾)
制定优先级清单,明确不同场景的响应级别。
备份与恢复策略
- 数据备份:遵循“3-2-1原则”(3份备份、2种介质、1份异地存储),推荐使用增量备份与全量备份结合。
- 系统镜像:定期创建操作系统快照(如VMware Snapshot、LVM快照),保存关键配置参数。
- 验证机制:每季度执行恢复演练,确保备份可用的有效性。
实时监控与告警系统

- 部署工具(如Prometheus、Zabbix)监控CPU、内存、磁盘I/O等指标。
- 设置阈值告警(如磁盘使用率达90%触发通知)。
- 日志集中管理(ELK Stack),便于故障回溯。
应急响应流程
故障发现 → 初步诊断(系统日志分析) → 启动预案 → 隔离故障节点 → 执行恢复操作 → 业务验证 → 生成事件报告
人员分工与培训
- 明确运维团队、安全团队、管理层职责,设立AB角机制。
- 每半年开展模拟演练(如红蓝对抗、灾难恢复沙盘推演)。
合规与文档管理
- 符合ISO 27001、等保2.0等标准。
- 维护《应急预案手册》,记录历史故障处理案例。
具体实施步骤
预防(Prevention)
- 部署冗余硬件(RAID、双电源)与负载均衡。
- 定期更新系统补丁,关闭非必要端口。
- 配置防火墙规则与载入检测系统(IDS)。
响应(Response)

- 故障定位:通过
dmesg(Linux)、事件查看器(Windows)分析日志。 - 应急措施:
- 系统崩溃→进入单用户模式修复或启动备用服务器。
- 勒索干扰→立即断网,使用备份恢复数据。
- 沟通机制:通过企业微信、钉钉等工具同步进展,避免信息滞后。
恢复(Recovery)
- 数据恢复后,对比哈希值校验完整性。
- 逐步恢复业务(优先核心服务,如数据库、支付系统)。
- 72小时内提交《故障分析报告》,优化预案。
最佳实践案例
- 某金融公司:采用双活架构(Active-Active),主备数据中心同步延迟<1秒,故障切换时间控制在30秒内。
- 某电商平台:通过Kubernetes实现容器化部署,结合自动化脚本(Ansible)完成故障节点替换,减少人工干预。
- 某政府机构:建立异地容灾中心,每季度与第三方安全机构联合演练,通过等保三级认证。
常见误区与规避方法
- 误区1:忽视预案测试→结果:备份失效。
规避:定期恢复演练,验证备份可用性。 - 误区2:过度依赖硬件冗余→结果:单点逻辑错误引发连锁故障。
规避:采用软件定义容灾(SDS)与多副本机制。 - 误区3:忽略人为因素→结果:操作失误导致数据丢失。
规避:实施权限分级与操作审计(如Auditd)。
引用说明
本文参考以下权威资料:
- NIST SP 800-184《网络事件恢复指南》
- 《信息系统灾难恢复规范》(GB/T 20988-2007)
- 2024年IDC《全球业务连续性调查报告》
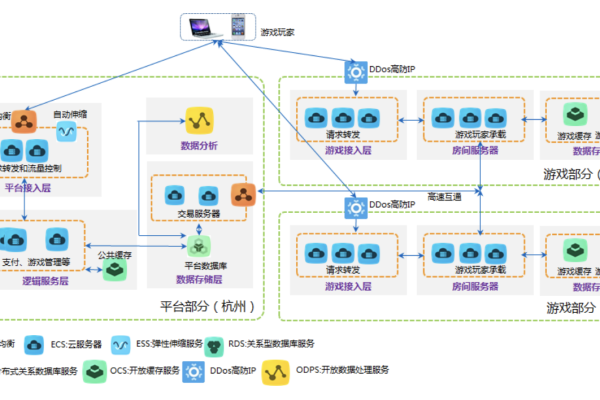


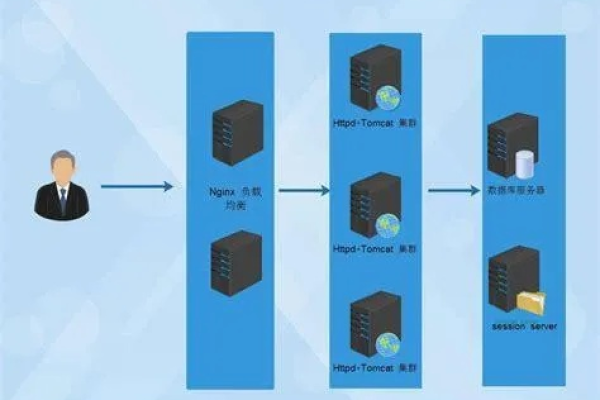


热门文章
-

云服务器在搭建实时报警平台中扮演什么角色?
2024-10-04 -

MySQL存储过程的高效使用与编写指南,如何优化C语言中的MySQL存储过程?
2025-03-08 -

配件网站模板_网站模板设置
2024-06-23 -

为什么服务器在技术世界中如此受到青睐?
2024-10-08 -

如何检查网络连接状态以确保设备已连接到互联网?
2025-03-01 -

如何轻松租用云服务器,关键步骤和技巧指南
2024-09-22 -

是否必须购买云数据库以配合云服务器使用?
2024-09-20 -

CFTPSSL证书是什么?它如何提升文件传输的安全性?
2024-12-15