服务器故障分类

服务器故障通常分为硬件、软件、网络及人为操作四类,硬件故障包括电源、硬盘或内存损坏;软件问题涉及系统崩溃、配置错误或兼容冲突;网络故障表现为连接中断、带宽不足或外部攻击;人为失误多由操作不当、误删数据或未及时维护引发,通过定期监控、冗余设计和规范流程可有效降低故障风险。
服务器故障分类与应对策略
在现代数字化场景中,服务器作为核心基础设施,其稳定性直接影响业务连续性,服务器故障的复杂性要求运维人员快速识别问题根源并采取针对性措施,以下是服务器故障的常见分类及相关解决方案:
硬件故障
硬件故障是服务器宕机的常见原因,通常表现为物理组件损坏或性能下降。
硬盘故障
- 症状:数据读取/写入错误、系统启动失败、SMART报警。
- 解决方案:
- 立即更换故障硬盘,使用RAID技术实现冗余备份。
- 定期检查硬盘健康状态(如CrystalDiskInfo工具)。
内存故障
- 症状:系统蓝屏、应用程序崩溃、日志报“ECC错误”。
- 解决方案:
- 通过MemTest86+进行内存条测试,更换损坏模块。
- 启用服务器内存镜像功能(如Intel® RAS技术)。
电源与散热问题

- 症状:服务器突然关机、风扇异响、CPU温度过高。
- 解决方案:
- 配置双路冗余电源(1+1或2+2模式)。
- 定期清理散热通道,部署机房温湿度监控系统。
软件与系统故障
软件层面的故障可能由配置错误、资源冲突或代码缺陷引发。
操作系统崩溃
- 症状:内核panic、启动卡在引导界面、文件系统损坏。
- 解决方案:
- 进入救援模式修复文件系统(如Linux的fsck命令)。
- 采用自动化配置管理工具(Ansible/Puppet)减少人为错误。
应用程序异常
- 症状:服务端口无响应、数据库连接池耗尽、日志报“内存泄漏”。
- 解决方案:
- 通过APM工具(如New Relic)监控线程状态与资源占用。
- 实施容器化部署(Docker/K8s)实现进程隔离与快速回滚。
补丁与兼容性问题

- 症状:更新后服务不可用、驱动冲突。
- 解决方案:
- 在测试环境中验证补丁兼容性,制定回退预案。
- 使用版本控制工具(Git)管理配置文件。
网络与安全故障
网络层故障可能导致服务器与外部系统失联或遭受攻击。
网络中断
- 症状:Ping超时、路由表丢失、网卡流量异常。
- 解决方案:
- 检查物理链路(网线/光纤),启用Bonding多网卡绑定。
- 部署BGP多线接入保障网络冗余。
DDoS攻击
- 症状:带宽占满、TCP连接数激增、合法用户无法访问。
- 解决方案:
- 启用云服务商的DDoS防护(如AWS Shield/Azure DDoS Protection)。
- 配置流量清洗规则,限制单个IP请求频率。
破绽利用

- 症状:异常进程活动、陌生端口开放、数据被加密勒索。
- 解决方案:
- 定期扫描破绽(Nessus/OpenVAS),及时修复CVE风险。
- 实施零信任架构(Zero Trust),强化访问控制策略。
人为操作失误
统计显示,30%的服务器故障由人为误操作导致(来源:Gartner 2022)。
- 典型场景:误删关键文件、错误配置防火墙、未授权变更。
- 规避方案:
- 推行权限分级制度,禁止直接使用root账户。
- 部署操作审计系统(如Auditd),记录所有SSH会话与命令历史。
环境与自然灾害
机房环境问题可能引发连锁故障:
- 电力中断:配置UPS+柴油发电机双保险,市电切换时间≤10ms。
- 火灾/水灾:采用烟雾探测与气体灭火系统,数据中心选址避开洪涝区。
预防优于修复:服务器运维黄金法则
- 自动化监控:集成Zabbix/Prometheus实时跟踪硬件健康度与性能指标。
- 灾备演练:每季度模拟灾难场景(如硬盘阵列失效),验证备份恢复流程。
- 文档沉淀:建立标准操作手册(SOP),记录所有故障处理案例。
引用说明
本文技术观点参考自:
- IBM《服务器硬件维护白皮书》(2024版)
- NIST《信息技术基础设施风险管理框架》
- 维基百科“服务器容错技术”词条(最后编辑于2024年1月)
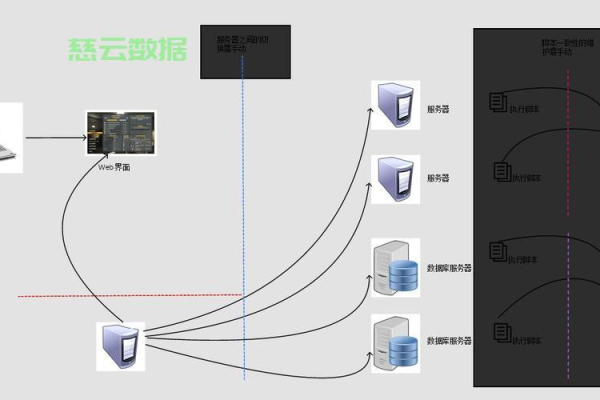



热门文章
-

云服务器在搭建实时报警平台中扮演什么角色?
2024-10-04 -

MySQL存储过程的高效使用与编写指南,如何优化C语言中的MySQL存储过程?
2025-03-08 -

为什么服务器在技术世界中如此受到青睐?
2024-10-08 -
配件网站模板_网站模板设置
2024-06-23 -

微信中拉黑某人后,其头像显示状态会有什么变化?
2024-11-12 -

如何检查网络连接状态以确保设备已连接到互联网?
2025-03-01 -

如何轻松租用云服务器,关键步骤和技巧指南
2024-09-22 -

QQ资料卡为何显示为空?原因何在?
2024-11-11