从队列取消息

从队列中获取消息是
消息
队列系统的核心操作,通常遵循先进先出原则,消费者通过主动拉取或服务端推送方式读取消息,确保异步通信、系统解耦和流量控制,处理时需考虑消息确认机制,防止数据丢失,常用于分布式系统、任务调度等场景。
在现代分布式系统中,消息队列(Message Queue)是解耦服务、提升系统可靠性的核心技术之一。从队列中取出消息这一行为看似简单,但其背后的机制和应用细节直接影响系统的吞吐量、容错能力和业务稳定性,以下内容将从技术原理、实现方式、常见场景及最佳实践展开说明。
消息队列的核心工作原理
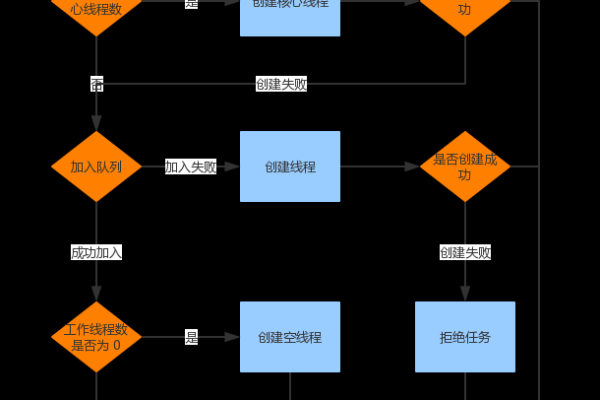
消息队列采用生产者-消费者模型,生产者负责向队列推送消息,消费者负责按需拉取消息,当消费者执行“取消息”操作时,系统需完成以下关键步骤:
- 建立连接:消费者与消息队列服务端建立通信(如通过TCP协议)。
- 订阅队列:明确监听的目标队列名称或主题(Topic)。
- 消息拉取:通过长轮询(Long Polling)或推送(Push)方式获取消息。
- 确认机制:消费者处理完成后,需向队列发送ACK(确认回执),确保消息被成功消费,避免重复投递。
常见的消息取出方式
不同消息队列中间件提供差异化的取消息策略,以下是三种典型模式:
主动拉取(Pull)
- 适用场景:需精确控制消费速率或批量处理的场景(如Kafka)。
- 实现方式:消费者定时调用
poll()方法从队列获取消息。 - 优点:灵活性高,消费者可自主决定拉取频率。
- 缺点:可能增加延迟,需处理空轮询问题。
服务端推送(Push)
- 适用场景:实时性要求高的业务(如RabbitMQ的AMQP协议)。
- 实现方式:服务端通过长连接主动向消费者推送消息。
- 优点:降低延迟,减少客户端资源消耗。
- 缺点:需处理消费者负载不均问题。
事件驱动(Event-Driven)
- 适用场景:微服务架构中的异步通信(如Redis Streams)。
- 实现方式:通过监听队列事件触发回调函数处理消息。
- 优点:资源利用率高,适合高并发场景。
- 缺点:需维护事件监听器的稳定性。
消息消费的容错与保障
从队列中取出消息后,需确保消息处理的可靠性,以下为关键保障机制:

ACK确认机制
消费者处理完消息后,显式发送ACK通知队列删除消息,若处理失败,队列会重新投递消息(至少一次交付语义)。死信队列(DLQ)
当消息多次重试仍失败时,将其转移到独立队列,供人工介入或后续分析。幂等性设计
消费者需保证重复消息不会引发副作用(如通过唯一ID去重)。
典型应用场景
- 异步任务处理
例如订单支付后,通过队列触发库存扣减、通知推送等操作。 - 流量削峰
突发流量写入队列,消费者按系统承载能力匀速处理。 - 跨系统解耦
微服务间通过队列传递数据,避免直接依赖。
最佳实践建议
- 控制并发数
根据消费者性能动态调整并发线程数,避免资源耗尽。 - 监控与告警
监控队列堆积情况(如积压消息数),设置阈值告警。 - 优雅关闭
消费者停机前需完成正在处理的消息,防止数据丢失。
常见问题解答
Q:消息被重复消费怎么办?
A:通过业务层幂等性设计(如数据库唯一约束)或记录已处理的全局消息ID。
Q:队列积压消息过多如何解决?
A:临时增加消费者实例,或排查消费者处理性能瓶颈(如数据库慢查询)。
Q:如何确保消息顺序性?
A:使用支持分区顺序的队列(如Kafka Partition),同一分区内的消息由单个消费者顺序处理。

引用说明
本文参考了以下技术文档:
- RabbitMQ官方文档(https://www.rabbitmq.com)
- Apache Kafka设计原理(https://kafka.apache.org/documentation)
- 《分布式系统:概念与设计》(第5版)





热门文章
-

云服务器在搭建实时报警平台中扮演什么角色?
2024-10-04 -

MySQL存储过程的高效使用与编写指南,如何优化C语言中的MySQL存储过程?
2025-03-08 -

配件网站模板_网站模板设置
2024-06-23 -

为什么服务器在技术世界中如此受到青睐?
2024-10-08 -

如何检查网络连接状态以确保设备已连接到互联网?
2025-03-01 -

如何轻松租用云服务器,关键步骤和技巧指南
2024-09-22 -

微信中拉黑某人后,其头像显示状态会有什么变化?
2024-11-12 -

是否必须购买云数据库以配合云服务器使用?
2024-09-20