如何有效使用FindLinux命令来搜索文件和目录?

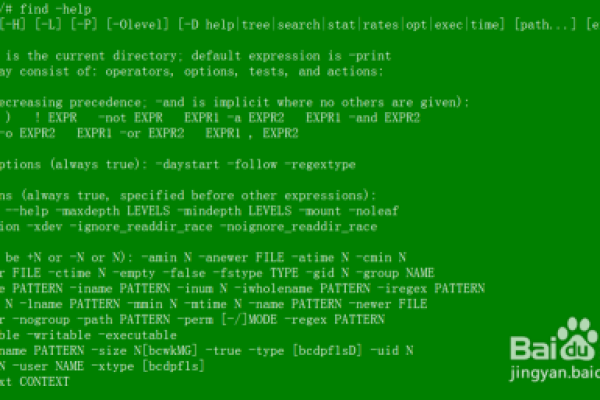
Linux系统中的find命令是一个功能强大且灵活的工具,用于在文件系统中搜索符合特定条件的文件或目录,通过结合各种选项和参数,find命令可以实现复杂的搜索需求,下面将详细介绍find命令的基本用法、常用选项以及一些实际应用场景。
一、基本语法
find命令的基本语法如下:
find [path] [expression]
[path]: 指定要搜索的起始目录。
[expression]: 指定搜索的标准或条件。
二、常用选项及示例
1. 按名称查找
精确匹配:-name "filename"
find /path/to/directory -name "filename.txt"
忽略大小写:-iname "filename"
find /path/to/directory -iname "filename.txt"
2. 按类型查找
查找文件:-type f
find /path/to/directory -type f
查找目录:-type d

find /path/to/directory -type d
查找符号链接:-type l
find /path/to/directory -type l
3. 按大小查找
大于指定大小:-size +N[cwbkMG]
find /path/to/directory -size +1M # 查找大于1MB的文件
小于指定大小:-size -N[cwbkMG]
find /path/to/directory -size -1M # 查找小于1MB的文件
4. 按修改时间查找
最近7天内修改的文件:-mtime -7
find /path/to/directory -mtime -7
超过7天未修改的文件:-mtime +7

find /path/to/directory -mtime +7
5. 按用户或组查找
查找由特定用户拥有的文件:-user username
find /path/to/directory -user root
查找由特定组拥有的文件:-group groupname
find /path/to/directory -group developers
6. 按权限查找
查找具有特定权限的文件:-perm mode
find /path/to/directory -perm 644 # 查找权限为644的文件
7. 执行操作
删除找到的文件:-exec rm {} ;

find /path/to/directory -name "*.tmp" -exec rm {} ;
复制找到的文件:-exec cp {} /destination ;
find /path/to/directory -name "*.txt" -exec cp {} /backup ;
三、组合条件
find命令支持使用逻辑运算符来组合多个条件,如AND (-a)、OR (-o)、NOT (!)等。
find /path/to/directory ( -name "*.txt" -o -name "*.pdf" ) # 查找以.txt或.pdf结尾的文件 find /path/to/directory ( -name "*.txt" -a -size +1M ) # 查找以.txt结尾且大小超过1MB的文件
四、FAQs
Q1: find命令中的{ }和;分别代表什么?
A1:{}是占位符,用于表示find命令找到的每一个文件名。;是命令结束的标志,告诉find命令后面的部分是一个单独的命令,由于;在shell中有特殊含义,所以需要用反斜杠进行转义。
Q2: find命令如何递归遍历子目录?
A2: find命令默认会递归遍历指定目录及其所有子目录,如果只想遍历到某一深度,可以使用-maxdepth或-mindepth选项来限制深度。find /path/to/directory -maxdepth 1只会遍历到一级子目录。
五、小编有话说
find命令是Linux系统中不可或缺的工具之一,掌握其基本用法和常用选项可以极大地提高工作效率,需要注意的是,由于find命令非常强大,使用时也要小心谨慎,特别是涉及到删除操作时,一定要确保命令正确无误,以免误删重要数据,建议在使用find命令前先使用-print选项预览将要操作的文件列表,确认无误后再执行实际的操作。



热门文章
-

云服务器在搭建实时报警平台中扮演什么角色?
2024-10-04 -

MySQL存储过程的高效使用与编写指南,如何优化C语言中的MySQL存储过程?
2025-03-08 -

为什么服务器在技术世界中如此受到青睐?
2024-10-08 -

配件网站模板_网站模板设置
2024-06-23 -

如何检查网络连接状态以确保设备已连接到互联网?
2025-03-01 -

如何轻松租用云服务器,关键步骤和技巧指南
2024-09-22 -

微信中拉黑某人后,其头像显示状态会有什么变化?
2024-11-12 -

是否必须购买云数据库以配合云服务器使用?
2024-09-20