上一篇
探索Shuffle,它如何改变我们的音乐体验?
“Shuffle” 是一个英文单词,意思是“洗牌”,也可以表示“随机播放”音乐。
Shuffle,这个词汇在现代科技和日常生活中扮演着越来越重要的角色,它不仅是一种随机化处理方式,更是一种优化算法、数据分析工具,甚至是娱乐和艺术创作的灵感来源,本文将深入探讨Shuffle的多个方面,从其定义、应用到技术实现,以及在不同领域中的具体案例。

一、Shuffle的定义与原理
1. Shuffle的基本概念
Shuffle,源自英语单词,意为“洗牌”或“混合”,在计算机科学中,Shuffle通常指的是对数据集进行随机排列或重新分布的过程,这一过程可以应用于多种场景,如数据预处理、并行计算、负载均衡等。
2. Shuffle的工作原理
Shuffle的核心在于随机性,通过一定的算法,将数据集中的每个元素分配到不同的组或位置上,以达到均匀分布的目的,常见的Shuffle算法包括Fisher-Yates Shuffle(费舍尔-耶茨洗牌算法)和Durstenfeld Shuffle(杜尔斯坦菲尔德洗牌算法),这些算法通过迭代交换元素的位置,确保每个元素都有相同的概率出现在任何一个位置上。
二、Shuffle在数据处理中的应用
1. 数据预处理
在数据挖掘和机器学习中,数据预处理是至关重要的一步,Shuffle常用于打乱数据集的顺序,以确保训练模型时不会受到数据顺序的影响,在训练神经网络时,通过Shuffle可以避免模型过拟合某些特定的数据模式。
2. 并行计算
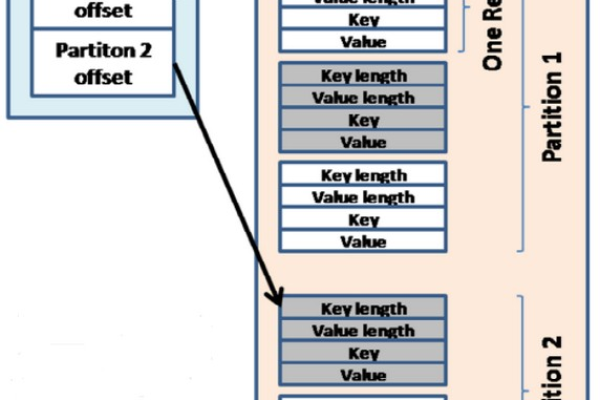
在分布式计算环境中,Shuffle用于将数据均匀分配到不同的计算节点上,以提高计算效率,在MapReduce框架中,Shuffle阶段负责将Map阶段的输出按照Key进行分组,并传输到Reduce阶段进行处理,通过Shuffle,可以有效地平衡各个节点的负载,提高整体计算性能。
3. 负载均衡
在网络通信和服务器集群中,Shuffle用于实现负载均衡,通过将请求或任务随机分配到不同的服务器或节点上,可以避免单个节点过载,从而提高系统的整体吞吐量和响应速度。
三、Shuffle的技术实现
1. 编程语言支持
大多数现代编程语言都提供了对Shuffle的支持,Python中的random.shuffle()函数、Java中的Collections.shuffle()方法、C++中的std::shuffle算法等,都可以方便地实现数据的随机排列。
2. 大数据框架
在大数据处理领域,Hadoop、Spark等框架都内置了Shuffle机制,Hadoop的MapReduce框架在Shuffle阶段会自动将Map输出的数据按照Key进行分组,并传输到Reduce阶段进行处理,Spark则提供了更为高效的内存计算能力,通过RDD(Resilient Distributed Dataset)的转换操作实现了数据的Shuffle。
3. 数据库系统
一些数据库系统也支持Shuffle操作,PostgreSQL和MySQL等关系型数据库可以通过SQL查询语句中的ORDER BY RANDOM()来实现数据的随机排序,NoSQL数据库如MongoDB也提供了类似的功能,通过聚合管道中的$sample阶段实现数据的随机抽样和Shuffle。
四、Shuffle在不同领域的应用案例
1. 金融行业
在金融行业中,Shuffle被广泛应用于风险管理和欺诈检测,通过对交易数据进行随机抽样和分析,可以发现潜在的风险模式和异常行为,从而及时采取措施防范风险。
2. 医疗健康
在医疗健康领域,Shuffle用于临床试验和药物研发,通过对患者数据进行随机分组和对照实验,可以评估新药或治疗方法的有效性和安全性,Shuffle还可以用于基因测序数据的处理和分析,帮助科学家发现新的遗传变异和疾病关联。
3. 娱乐产业
在娱乐产业中,Shuffle是音乐播放器和视频流媒体平台的常见功能,用户可以通过Shuffle模式随机播放音乐或视频内容,增加听歌或观影的乐趣,Shuffle还被用于游戏开发中,通过随机生成地图、敌人和道具等元素,提高游戏的可玩性和挑战性。
五、Shuffle的未来发展趋势
随着大数据、人工智能和云计算等技术的不断发展,Shuffle的应用前景将更加广阔,我们可以期待以下几个方面的发展:
1、更高效的Shuffle算法:随着数据量的不断增加和计算需求的不断提高,需要更高效的Shuffle算法来处理大规模数据集,未来的研究将致力于开发更快速、更节省资源的Shuffle算法。
2、智能化的Shuffle策略:结合机器学习和人工智能技术,可以实现更加智能化的Shuffle策略,根据数据的特征和分布情况自动选择最优的Shuffle方法和参数设置。
3、跨平台和跨系统的Shuffle集成:随着多云环境和混合云架构的普及,需要实现跨平台和跨系统的Shuffle集成,未来的Shuffle技术将更加注重兼容性和互操作性,以适应不同的计算环境和需求。
4、隐私保护和安全性:在处理敏感数据时,需要确保Shuffle过程的安全性和隐私保护,未来的Shuffle技术将更加注重数据加密、访问控制和审计等方面的安全措施。
六、相关问答FAQs
Q1: Shuffle是否总是必要的?
A1: Shuffle并不是在所有情况下都是必要的,是否需要使用Shuffle取决于具体的应用场景和需求,在数据分析和机器学习中,Shuffle通常用于避免数据顺序带来的偏差;而在实时数据处理和流式计算中,可能更注重数据的时效性和连续性,此时Shuffle可能不是首要考虑的因素,在使用Shuffle之前,需要仔细评估其必要性和对系统性能的影响。
Q2: Shuffle过程中如何保证数据的完整性和一致性?
A2: 在Shuffle过程中保证数据的完整性和一致性是非常重要的,这通常通过以下几种方式实现:使用可靠的数据传输协议和机制(如TCP/IP协议)来确保数据在传输过程中不丢失或损坏;在接收端进行数据校验和验证(如哈希校验、CRC校验等)以确保数据的正确性和完整性;对于关键数据或敏感数据,还可以采用冗余存储和备份策略来进一步提高数据的可靠性和安全性,在分布式系统中还需要考虑数据的一致性问题,通常通过分布式锁、事务管理等机制来确保多个节点之间的数据一致性。
以上就是关于“shuffle”的问题,朋友们可以点击主页了解更多内容,希望可以够帮助大家!
本站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本站,有问题联系侵删!
本文链接:http://www.xixizhuji.com/fuzhu/360947.html