上一篇
事务隔离级别如何影响数据库并发操作?
事务隔离级别是数据库管理系统中用于控制并发事务间相互干扰程度的机制,包括读未提交、读已提交、可重复读和串行化四种。
事务隔离级别是数据库管理系统中的一个重要概念,用于确保并发事务的一致性和数据完整性,本文将详细介绍事务隔离级别的定义、分类及其在实际应用中的影响。

一、事务隔离级别
事务隔离级别决定了一个事务与其他事务之间的独立性程度,不同的隔离级别可以提供不同程度的保护,以避免脏读、不可重复读和幻读等问题,以下是四种常见的事务隔离级别:
1、Read Uncommitted(未提交读)
2、Read Committed(已提交读)
3、Repeatable Read(可重复读)
4、Serializable(可串行化)
二、各事务隔离级别详解
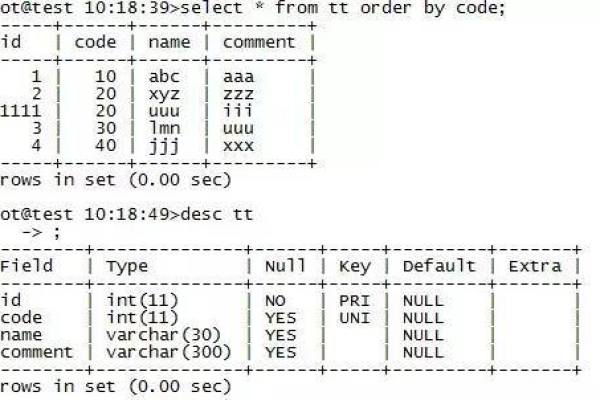
| 隔离级别 | 脏读 | 不可重复读 | 幻读 | 性能 |
| Read Uncommitted | 可能 | 可能 | 可能 | 高 |
| Read Committed | 不可能 | 可能 | 可能 | 中 |
| Repeatable Read | 不可能 | 不可能 | 可能 | 低 |
| Serializable | 不可能 | 不可能 | 不可能 | 最低 |
1. Read Uncommitted(未提交读)
在这种隔离级别下,事务可以读取其他事务尚未提交的数据,这种级别的隔离性能最高,但会导致脏读现象。
示例:
假设有两个事务T1和T2,T1正在修改数据A,但尚未提交,此时T2读取了数据A的未提交版本,如果T1最终回滚,那么T2读取到的就是一个脏数据。
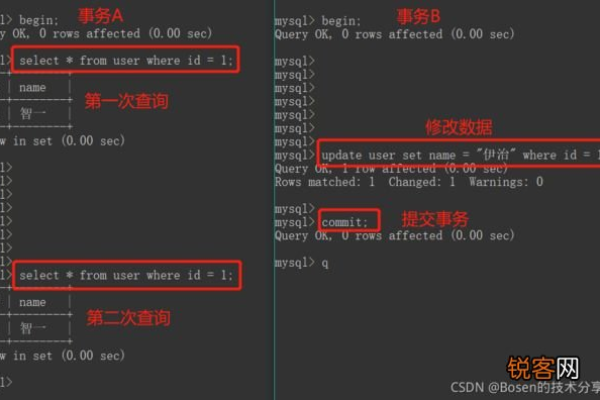
2. Read Committed(已提交读)
在这种隔离级别下,事务只能读取其他事务已经提交的数据,这种级别的隔离避免了脏读,但可能会发生不可重复读。
示例:
假设有两个事务T1和T2,T1读取了数据A的值,然后T2修改了数据A并提交,此时T1再次读取数据A时,会发现值与第一次读取的不同。
3. Repeatable Read(可重复读)
在这种隔离级别下,事务在其执行期间多次读取同一数据时,结果应该是一致的,这种级别的隔离避免了脏读和不可重复读,但可能会发生幻读。
示例:
假设有两个事务T1和T2,T1读取了数据A的值,然后T2插入了一条新的记录,这条新记录满足T1的查询条件,当T1再次查询时,会发现多了一条记录。
4. Serializable(可串行化)
这是最高的隔离级别,完全避免了脏读、不可重复读和幻读,事务按照顺序一个接一个地执行,仿佛它们是在一个没有其他并发事务的环境中运行的。
示例:
在这种隔离级别下,所有事务都是完全串行化的,不存在并发问题,但性能也是最低的。
三、事务隔离级别的选择
选择合适的事务隔离级别需要权衡数据的一致性和系统的性能,更高的隔离级别意味着更强的数据一致性保障,但同时也会带来更大的性能开销。
对于大多数应用来说,Read Committed是一个合理的默认选择,因为它提供了足够的数据一致性保障,同时性能也相对不错。
对于金融等对一致性要求极高的系统,可能需要使用Repeatable Read或Serializable。
对于一些对性能要求极高的场景,可以考虑使用Read Uncommitted,但要非常小心处理可能出现的脏读问题。
四、相关问答FAQs
Q1: 为什么需要不同的事务隔离级别?
A1: 不同的事务隔离级别提供了不同程度的数据一致性保障和性能平衡,根据应用的具体需求,可以选择最适合的隔离级别来确保数据的一致性和系统的性能。
Q2: 如何在实际项目中选择合适的事务隔离级别?
A2: 在实际项目中,选择合适的事务隔离级别需要考虑以下几个方面:
数据一致性要求:根据业务逻辑的需要,确定可以接受的数据不一致的程度。
系统性能:评估不同隔离级别对系统性能的影响,特别是在高并发场景下。
测试和调优:通过实际测试和调优,找到最佳的平衡点。
事务隔离级别是数据库设计中的一个重要考虑因素,合理选择和使用事务隔离级别可以有效提高系统的可靠性和性能。
以上内容就是解答有关“事务隔离级别”的详细内容了,我相信这篇文章可以为您解决一些疑惑,有任何问题欢迎留言反馈,谢谢阅读。
本站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本站,有问题联系侵删!
本文链接:http://www.xixizhuji.com/fuzhu/358298.html