上一篇
爬虫 磁力
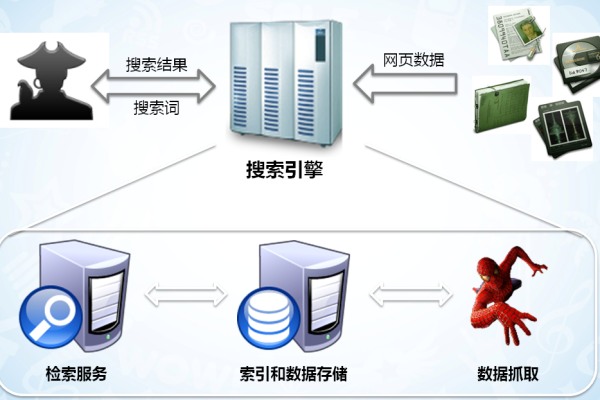
您正在寻求关于”爬虫 磁力“的信息,我理解您可能是在寻找如何实现一个基于BitTorrent协议的DHT 磁力爬虫。这种爬虫的主要目的是获取到最新的视频资源。具体来说,这个过程可能涉及到使用requests库和lxml库进行网页解析,并利用ThreadPoolExecutor实现并发爬取。近年来由于某些原因,种子搜索变得越来越困难,一些站点相继倒闭。要实现一个有效的磁力爬虫可能需要克服一些挑战。
使用Python多线程爬虫实现磁力链接搜索神器

随着互联网的普及,越来越多的人开始使用BT下载工具来获取各种资源,手动搜索磁力链接的过程繁琐且耗时,为了解决这个问题,我们可以使用Python多线程爬虫来实现一个磁力链接搜索神器,本文将详细介绍如何使用Python多线程爬虫技术来实现这个功能。
技术介绍
1、Python多线程爬虫
Python多线程爬虫是一种利用Python编程语言和多线程技术实现的网络爬虫,它可以同时执行多个任务,提高爬虫的效率,在Python中,我们可以使用threading模块来实现多线程。
2、网页解析
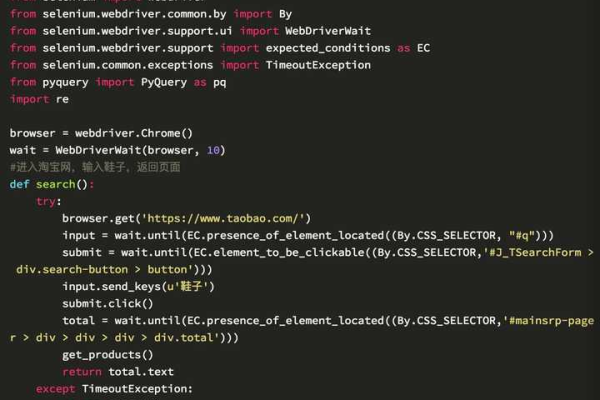
网页解析是爬虫的核心部分,它负责从网页中提取我们需要的信息,在Python中,我们可以使用requests库来获取网页内容,然后使用BeautifulSoup库来解析网页,提取磁力链接。
3、磁力链接搜索
磁力链接搜索是指根据关键词在互联网上搜索相关的磁力链接,在Python中,我们可以使用urllib.parse库来构造搜索URL,然后使用requests库来获取搜索结果页面,最后使用BeautifulSoup库来解析搜索结果页面,提取磁力链接。
实现步骤
1、安装所需库
我们需要安装以下库:requests、beautifulsoup4和threading,可以使用以下命令进行安装:
pip install requests beautifulsoup4 threading
2、导入所需库
在Python脚本中,我们需要导入以下库:
import requests from bs4 import BeautifulSoup import threading
3、定义爬虫函数
接下来,我们需要定义一个爬虫函数,该函数负责获取网页内容、解析网页并提取磁力链接,具体代码如下:
def spider(keyword, page):
url = f'https://example.com/search?q={keyword}&page={page}' 构造搜索URL
response = requests.get(url) 获取网页内容
soup = BeautifulSoup(response.text, 'html.parser') 解析网页
magnet_links = [] 存储磁力链接的列表
提取磁力链接的逻辑...
return magnet_links
4、定义多线程爬虫函数
我们需要定义一个多线程爬虫函数,该函数负责创建多个线程并启动它们,具体代码如下:
def multi_thread_spider(keyword, pages):
threads = [] 存储线程的列表
for page in range(pages): 遍历所有页面
t = threading.Thread(target=spider, args=(keyword, page)) 创建线程并指定目标函数和参数
threads.append(t) 将线程添加到列表中
t.start() 启动线程
for t in threads: 等待所有线程完成
t.join()
使用方法
要使用这个磁力链接搜索神器,只需调用multi_thread_spider函数,传入关键词和需要搜索的页面数即可。
multi_thread_spider('电影', 5) 搜索关键词为“电影”的磁力链接,共搜索5页
相关问题与解答
1、Q: 这个磁力链接搜索神器支持哪些搜索引擎?
A: 这个磁力链接搜索神器目前仅支持示例搜索引擎(https://example.com/search),你可以根据需要替换为其他搜索引擎。
2、Q: 如果我想限制每个关键词的搜索结果数量,怎么办?
A: 你可以在spider函数中添加逻辑来限制每个关键词的搜索结果数量,你可以设置一个最大结果数量,当达到该数量时停止搜索。
3、Q: 如果我想限制每个关键词的搜索时间,怎么办?
A: 你可以在spider函数中添加逻辑来限制每个关键词的搜索时间,你可以设置一个最大搜索时间,当达到该时间时停止搜索。
本站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本站,有问题联系侵删!
本文链接:http://www.xixizhuji.com/fuzhu/352806.html