
上一篇
love怎么注册域名,2000年怎么注册域名
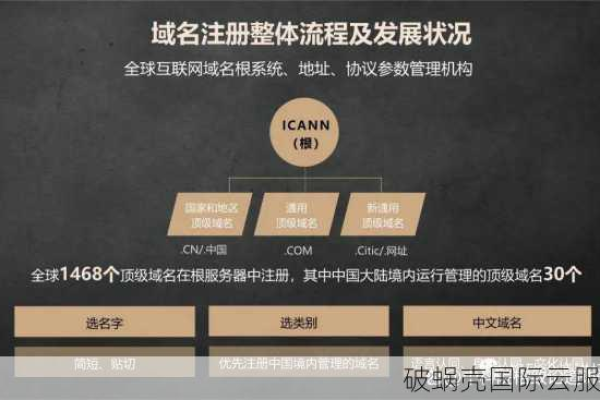
# 如何在2023年注册域名

在当今的数字时代,拥有自己的域名是许多企业或个人品牌战略的重要组成部分,域名是你的在线身份的地址,让人们可以找到你的网站、电子邮件或社交媒体账户,下面是关于如何注册域名的详细步骤:
第一步:确定你想要的域名
你需要决定你想要的域名,这应该是一个独特且易于记忆的名称,反映你的品牌或业务,你可以在网上搜索可用的域名,并使用各种域名注册服务进行比较。
第二步:选择一个域名注册商
有许多不同的域名注册商可供选择,包括GoDaddy、Namecheap、Google Domains等,每个注册商都有自己的费用结构和注册流程,所以选择一个最适合你需求的注册商非常重要,一些注册商可能会提供更便宜的价格,但可能缺乏某些功能或客户服务;其他注册商可能会提供更多的功能和优秀的客户服务,但价格可能会更高。
第三步:检查域名的可用性
在你选择的注册商网站上输入你想要的域名,然后查看该域名是否可用,如果你的域名已经被其他人注册了,那么你可能需要修改你的域名,或者考虑其他的选项。
第四步:购买域名
一旦你找到一个可用的域名,你就可以购买它了,大多数注册商会提供一个界面让你支付费用,并提供一份确认邮件,证明你已经成功购买了域名。
第五步:设置DNS记录
购买域名后,你需要设置DNS(域名系统)记录,这样人们就可以通过你的域名访问你的网站,这通常涉及将你的域名指向你的网站的IP地址,这个过程可能会有点复杂,特别是对于非技术用户来说,但是大多数注册商都会提供详细的说明和帮助。
2000年怎么注册域名?
回到2000年,互联网刚刚进入主流社会的视野,那时的域名注册过程与现在相比要复杂得多,那时候,人们主要通过专门的域名注册机构来注册域名,这些机构需要收取一定的费用,并且需要通过电话或邮寄的方式提交申请,由于互联网的用户数量相对较少,因此可用的顶级域名(TLD)也比现在少很多。
即使在那个时代,域名的重要性也开始显现出来,许多公司和个人开始意识到,拥有自己的.com或其他顶级域名可以提升他们的在线形象,并吸引更多的客户,尽管注册过程可能比现在复杂和昂贵,但仍有大量的人选择注册自己的域名。
相关问题与解答:
1. 问题:我应该如何选择一个合适的域名注册商?
选择一个合适的域名注册商需要考虑多个因素,你应该研究各个注册商的费用结构,看看哪个最适合你的预算,你也应该考虑注册商提供的客户服务的质量,你可能还需要考虑注册商是否提供任何附加服务,如网站建设工具或SSL证书。
2. 问题:我如何确定我想要的域名是否可用?
大多数域名注册商都提供了一个搜索工具,你可以输入你想要的域名进行检查,如果该域名已被其他人注册,那么它将显示为“已售出”或类似的信息,一些注册商还提供了预订服务,你可以预订一个即将到期的域名,然后在它到期时立即进行购买。
3. 问题:我购买了一个域名,但我不确定如何设置DNS记录,我应该怎么做?
设置DNS记录通常涉及到在你的主机提供商的控制面板中添加一个新的A记录或CNAME记录,这通常会涉及到输入你的域名和你的网站服务器的IP地址,如果你对此感到困惑,你可以联系你的主机提供商寻求帮助。
4. 问题:我在2000年就注册了我的第一个域名,但现在我已经忘记了我的密码和相关信息,我应该怎么办?
如果你忘记了密码和相关信息,你可以尝试通过你的域名注册商进行恢复,大多数注册商会要求你提供一些验证信息来证明你是该域名的所有者,如果你无法通过这种方式恢复你的信息,那么你可能需要联系注册商的客服部门以获取进一步的帮助。
本站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本站,有问题联系侵删!
本文链接:http://www.xixizhuji.com/fuzhu/352743.html
相关文章
-
怎么注册域名最好,2000年怎么注册域名_注册域名的流程
-
怎么注册域名最好,2000年怎么注册域名_如何注册域名挣钱
-

怎么注册域名后缀,2000年怎么注册域名
-
网址域名怎么注册,怎么注册网址2022年更新(网址域名怎么注册,怎么注册网址2022年更新)
-
windows中goldwave怎么降噪提高人声(goldwave怎么使用)(怎样用goldwave给人声降噪)
-
matplotlib.pyplot用法,扩展库matplotlib.pyplot中的函数plot(matplotlib.pyplot库没办法用)
-

如何注册域名才不会要钱,怎么注册域名,要钱吗(怎么样注册域名免费)
-
导入ova文件后怎么用_如何将OVF、OVA文件导入云平台?








