显卡3060多少钱

显卡3060的价格因品牌和型号而异,一般在2000-4000元之间。具体价格还需查看市场行情。
显卡作为电脑硬件中的重要组成部分,其价格受到多种因素的影响,包括市场需求、芯片供应情况、品牌策略等,尤其是NVIDIA的GeForce RTX 3060,自推出以来就因其出色的性能和相对合理的定价而受到广大消费者和游戏玩家的关注。
目前,RTX 3060的价格受市场波动影响较大,因此提供一个准确的价格是比较困难的,不过,我们可以从以下几个方面来分析和了解RTX 3060的价格走势。
RTX 3060发行价
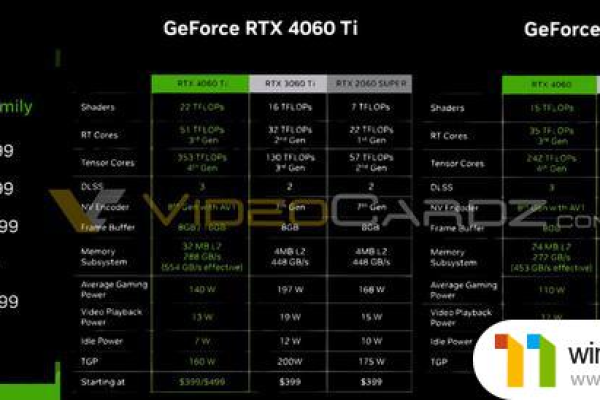
NVIDIA GeForce RTX 3060在发行之初的建议零售价(MSRP)通常设置在一个相对中等的水平,以吸引那些追求高性能但预算有限的用户,发行价因地区和合作伙伴的不同而有所差异,但通常在300到400美元之间。
市场供需状况
显卡价格受供需关系影响极大,当比特币或其他加密货币挖矿需求高涨时,显卡价格会因为挖矿市场的抢购而水涨船高,全球芯片短缺也对显卡的生产和供应造成了影响,这同样会推高显卡的市场价格。
第三方卖家和零售商定价
不同的零售商和第三方卖家可能会根据库存、竞争和利润策略来调整价格,零售商为了快速清理库存,可能会提供折扣促销;而在显卡供不应求的情况下,一些卖家则可能会趁机抬高价格。

新版本发布与价格变动
随着新的显卡系列或更新版本的发布,旧版显卡的价格通常会有所下降,这是因为新显卡通常带来更好的性能或性价比,使得旧版显卡相对不那么有吸引力。
当前RTX 3060的价格范围
截至目前,RTX 3060的具体价格因地区、销售渠道和可用性而异,在一些地区,它的售价可能略高于发行价,而在其他地区,由于供应增加或需求下降,价格可能已经趋于稳定甚至出现下降。
相关问题与解答
Q1: RTX 3060与上一代产品相比性能提升了多少?

A1: RTX 3060相较于上一代产品如RTX 2060有着显著的性能提升,根据官方数据和第三方评测,性能提升幅度大致在10%到25%之间,具体取决于游戏或应用程序。
Q2: 现在购买RTX 3060是否划算?
A2: 这取决于您的使用需求和预算,如果您需要一款性价比高的显卡来进行游戏或专业工作,且当前价格符合您的预算,那么现在购买是合适的,不过,如果您愿意等待,可能会有新一代产品发布或现有产品降价的机会。
Q3: RTX 3060适合用于哪些类型的游戏和应用?
A3: RTX 3060适用于大多数现代游戏,能够在1080p和1440p分辨率下提供超过60帧每秒的流畅体验,它还支持光线追踪和DLSS技术,可以提供更加逼真的视觉效果,对于视频编辑、3D渲染等专业应用来说,RTX 3060也是一个不错的选择。

Q4: 如果RTX 3060缺货,有没有类似的替代产品推荐?
A4: 当RTX 3060缺货或价格不理想时,您可以考虑类似性能的其他品牌显卡,如AMD的Radeon RX 6700 XT或RX 6600 XT,这些显卡通常提供与RTX 3060相似的游戏体验,但价格和可用性可能会有所不同。
RTX 3060的价格随市场变化而波动,购买时应考虑个人需求和当前市场状况,关注行业新闻和技术发展可以帮助您做出更明智的购买决策。