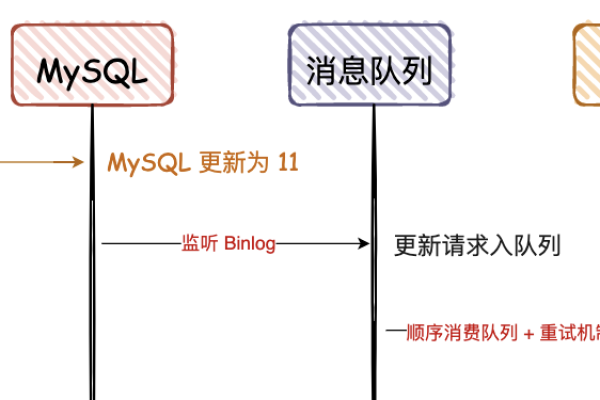
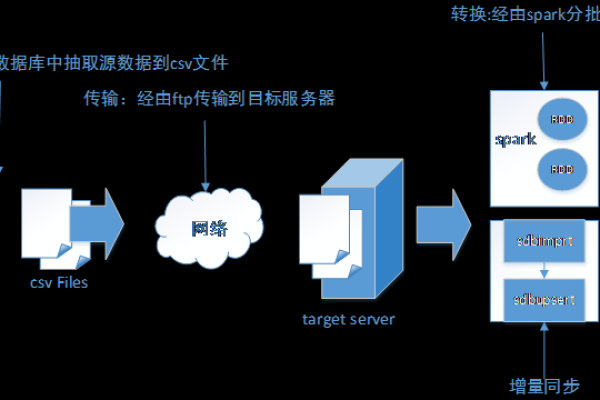
上一篇
最大堆建立过程,建立初始堆的完整过程
最大堆是一种特殊的完全二叉树,它的每个节点的值都大于或等于其子节点的值,在最大堆中,父节点的值总是大于或等于其子节点的值,最大堆通常用于实现优先队列,其中优先级最高的元素总是位于堆的顶部。
建立最大堆的过程可以分为两个步骤:将数组转换为最大堆;然后,调整堆以满足最大堆的性质。
1. 将数组转换为最大堆
我们需要找到数组的最后一个非叶子节点,这个节点的索引为`n/2`,我们从这个节点开始,向下遍历数组,对于每个节点,我们将其与其子节点进行比较,如果它小于其任何一个子节点,我们就交换它和该子节点的位置,这个过程会一直持续到根节点。
2. 调整堆以满足最大堆的性质
在将数组转换为最大堆的过程中,我们可能会破坏堆的性质,如果我们在交换节点后发现,新的根节点的值小于其子节点的值,那么我们就需要再次交换这两个节点的位置,这个过程会一直持续到堆满足最大堆的性质为止。
以下是建立最大堆的Python代码:
def build_max_heap(arr):
n = len(arr)
for i in range(n//2, -1, -1):
heapify(arr, n, i)
return arr
def heapify(arr, n, i):
largest = i
left = 2 * i + 1
right = 2 * i + 2
if left < n and arr[i] < arr[left]:
largest = left
if right < n and arr[largest] < arr[right]:
largest = right
if largest != i:
arr[i], arr[largest] = arr[largest], arr[i]
heapify(arr, n, largest)
在这个代码中,`build_max_heap`函数接受一个数组作为参数,然后调用`heapify`函数来建立最大堆,`heapify`函数接受一个数组、数组的长度和一个索引作为参数,然后它会检查当前节点是否满足最大堆的性质,如果不满足,它就会对当前节点进行下沉操作,直到满足最大堆的性质为止。
问题与解答:
1. 问:为什么我们需要从最后一个非叶子节点开始建立最大堆?
答:因为最后一个非叶子节点是最大的叶子节点的父节点,如果我们从这个节点开始建立最大堆,那么我们就可以保证所有的叶子节点都是最大的。
2. 问:为什么我们在交换节点后需要再次检查堆的性质?
答:因为在交换节点后,我们可能会破坏堆的性质,如果我们在交换节点后发现,新的根节点的值小于其子节点的值,那么我们就需要再次交换这两个节点的位置,这个过程会一直持续到堆满足最大堆的性质为止。
3. 问:为什么我们需要使用`heapify`函数来建立最大堆?
答:因为`heapify`函数可以帮助我们确保每个节点都满足最大堆的性质,如果我们直接交换节点的位置,那么我们可能会破坏堆的性质,通过使用`heapify`函数,我们可以确保每次交换节点的位置后,都会重新检查并调整堆,以确保它满足最大堆的性质。
4. 问:为什么我们需要在`heapify`函数中使用递归?
答:因为我们需要确保每个节点都满足最大堆的性质,如果我们只交换了当前节点的位置,而没有检查和调整其他节点的位置,那么我们可能会破坏堆的性质,通过使用递归,我们可以确保每次交换节点的位置后,都会重新检查并调整整个堆,以确保它满足最大堆的性质。
本站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本站,有问题联系侵删!
本文链接:http://www.xixizhuji.com/fuzhu/351495.html