
上一篇
独立站和平台的区别
独立站平台对比,平台站与独立站的优缺点

在当前的电商市场中,独立站和平台站是两种常见的销售模式,它们各自具有一定的优势和劣势,企业在选择时需要根据自身的实际情况进行权衡,本文将对这两种模式进行详细的对比分析,以帮助企业更好地了解它们的特点和适用场景。
一、独立站
1. 优点:
(1)品牌自主权:独立站可以让企业完全拥有自己的品牌,可以自由地进行品牌推广和营销活动,不受第三方平台的约束。
(2)客户数据:独立站可以收集到所有访问者的数据,包括访问时间、浏览内容、购买行为等,有助于企业更好地了解客户需求,进行精准营销。
(3)利润空间:独立站不需要支付平台佣金,企业可以保留更高的利润空间。
(4)产品定价:独立站可以根据市场需求和竞争情况,自主制定产品价格,不受平台价格战的影响。
2. 缺点:
(1)流量获取:独立站需要企业自己承担流量获取的成本,包括广告投放、搜索引擎优化等,相对于平台站来说,成本较高。
(2)技术支持:独立站需要企业自己开发和维护网站,技术难度较大,需要投入较多的人力和物力。
(3)信任度:相较于知名电商平台,独立站的信任度较低,消费者可能会担心购物安全和售后服务问题。
二、平台站
(1)流量支持:平台站通常具有庞大的用户基数,企业可以通过平台获得大量的潜在客户,降低流量获取成本。
(2)信任度:知名电商平台具有较高的信任度,消费者更愿意在这些平台上购物。
(3)技术支持:平台站提供一站式的电商解决方案,包括网站建设、支付系统、物流服务等,企业无需投入大量资源进行技术开发和维护。
(4)市场推广:平台站通常会为商家提供各种营销工具和资源,帮助企业扩大品牌知名度和市场份额。
(1)品牌限制:在平台站上销售的企业需要遵守平台的规则,无法完全展示自己的品牌形象。
(2)佣金成本:平台站通常会收取一定比例的佣金,企业的利润空间受到一定程度的压缩。
(3)价格竞争:平台站上众多商家之间的竞争激烈,可能导致价格战,影响企业的盈利水平。
(4)客户数据:平台站会收集到企业的客户数据,但企业无法完全掌握这些数据,可能影响后续的营销活动。
独立站和平台站在品牌自主权、客户数据、利润空间、产品定价等方面存在一定的差异,企业在选择销售模式时,需要根据自身的品牌定位、市场目标、资源条件等因素进行综合考虑,对于具有较强品牌意识和技术支持能力的企业,可以选择独立站模式;而对于希望快速进入市场、降低运营成本的企业,可以选择平台站模式。
四、相关问题与解答
1. Q:独立站和平台站在运营成本上有什么区别?
A:独立站需要企业自己承担流量获取、技术开发等方面的成本,而平台站则可以为商家提供一站式的电商解决方案,降低运营成本。
2. Q:独立站和平台站在客户信任度上有什么区别?
A:知名电商平台具有较高的信任度,消费者更愿意在这些平台上购物;而独立站的信任度相对较低,需要企业通过品牌建设和优质服务来提高消费者的信任度。
3. Q:独立站和平台站在产品定价上有什么区别?
A:独立站可以根据市场需求和竞争情况自主制定产品价格,不受平台价格战的影响;而平台站上众多商家之间的竞争激烈,可能导致价格战,影响企业的盈利水平。
本站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本站,有问题联系侵删!
本文链接:http://www.xixizhuji.com/fuzhu/350729.html
相关文章
-
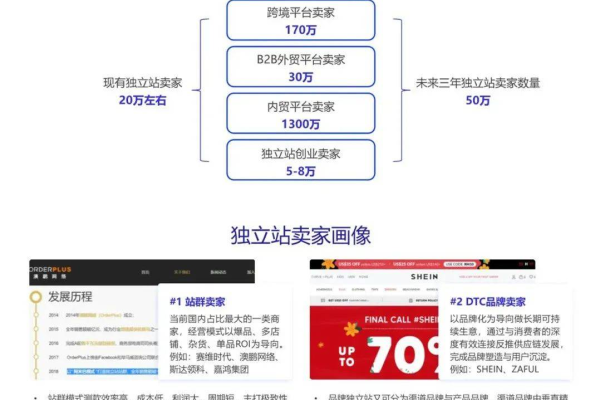
跨境独立站有哪些,跨境贸易独立站2022年更新(跨境独立站有哪些,跨境贸易独立站2022年更新了吗)
-

跨境独立站平台(海外独立站平台)(跨境独立站是什么)
-
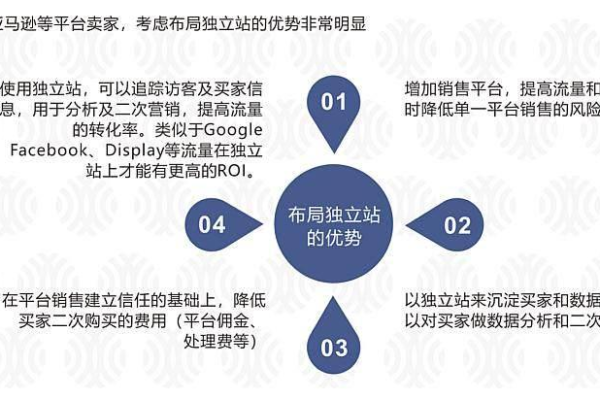
外贸独立站的优势,外贸独立站的优势和劣势2022年更新(外贸独立站的前景)
-

外贸独立站什么意思?外贸独立站建站有什么好处?(外贸做独立站好做吗?)
-

外贸独立站建站(外贸独立站建站培训班)(外贸独立站建站工具)
-

shopify独立站需要多少钱,独立站SHOPIFY,shopify独立站运营岗位好做吗
-

shopify独立站(shopify独立站 和 fb广告投放 相关内容)(shopify独立站如何运营)
-
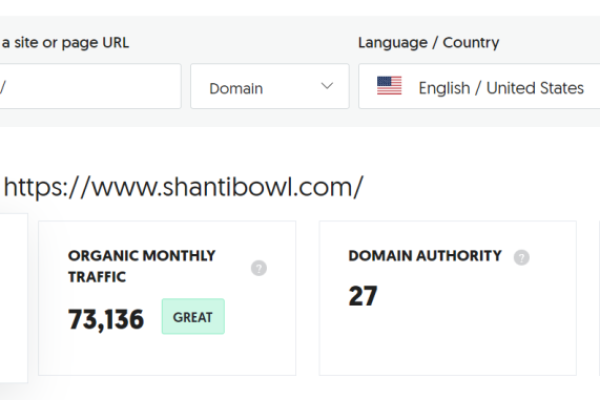
外贸独立站(外贸独立站怎么做)(外贸独立站做什么比较赚钱)








