上一篇
域名企业
域名企业,顾名思义,就是专门从事域名注册、交易、管理等业务的企业,随着互联网的普及和发展,域名已经成为了企业和个人在互联网上的重要标识,对于企业的品牌建设和网络营销具有重要意义,域名企业应运而生,为广大客户提供了专业、便捷的域名服务。

我们来了解一下域名的基本概念,又称为网址,是互联网上用于识别和定位计算机的层次结构式的字符标识,通常由一串用点分隔的名字组成,如www.example.com,域名是企业在互联网上的门面,是用户访问企业网站的重要途径,一个好的域名不仅能够提高企业的知名度,还能够为企业带来更多的客户资源。
域名企业的主要业务包括以下几个方面:
1. 域名注册:域名企业为客户提供各种顶级域名(如.com、.cn等)的注册服务,客户可以根据自己的需求选择合适的域名进行注册,域名企业会协助客户完成域名的申请、审核、缴费等流程。
2. 域名交易:域名企业提供域名的买卖交易平台,客户可以在平台上发布或购买自己心仪的域名,域名企业会对交易过程进行监管,确保交易的安全、合法。
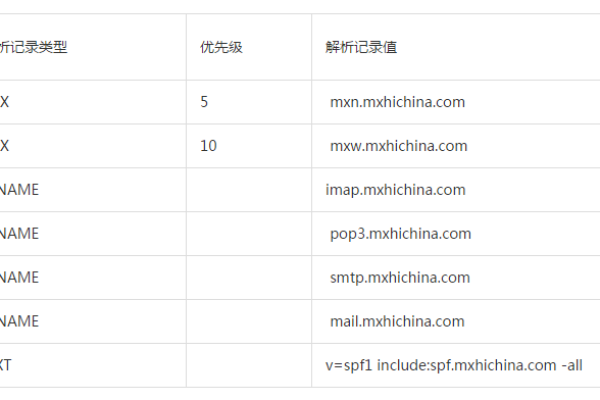
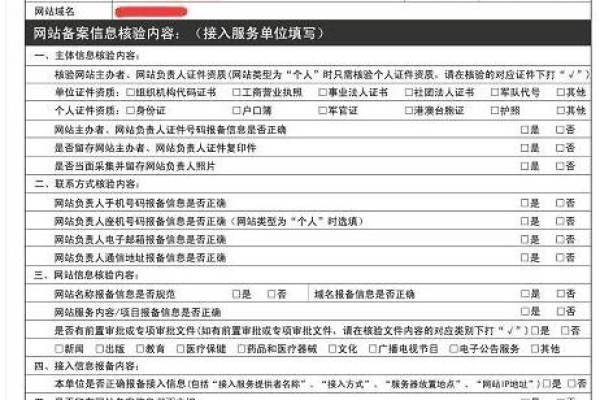
3. 域名管理:域名企业为客户提供一站式的域名管理服务,包括域名解析、DNS设置、备案等,客户可以通过域名企业管理平台轻松管理自己的域名,无需担心繁琐的操作流程。
4. 网站建设与优化:除了域名服务外,域名企业还为客户提供网站建设、优化等服务,客户可以根据自己的需求选择合适的网站模板,快速搭建自己的网站,域名企业还会为客户提供网站优化建议,帮助客户提高网站的搜索引擎排名,吸引更多的流量。
5. 其他增值服务:域名企业还为客户提供一些增值服务,如SSL证书、邮箱服务等,这些服务可以帮助客户提高网站的安全性和专业性,提升用户体验。
域名企业为客户提供了全方位的域名服务,帮助企业和个人在互联网上建立自己的品牌和形象,随着互联网的不断发展,域名企业将会发挥越来越重要的作用。
相关问题与解答:
1. 什么是顶级域名?
答:顶级域名(Top-level Domain,简称TLD)是互联网上最高一级的域名,如.com、.cn等,顶级域名之下还有二级域名、三级域名等,如www.example.com中的example就是二级域名。
2. 为什么要选择一个好的域名?
答:一个好的域名不仅能够提高企业的知名度,还能够为企业带来更多的客户资源,一个好的域名应该简洁易记、与企业品牌相关联,便于用户记忆和传播。
3. 如何选择合适的域名?
答:选择合适的域名需要考虑以下几个因素:与品牌相关联、简洁易记、易于拼写和发音、避免侵权等,还可以参考同行业的优秀企业的域名,学习借鉴其经验。
4. 如何保证域名的安全?
答:为了保证域名的安全,可以采取以下措施:使用可靠的域名注册商;定期检查域名的解析记录,确保没有被反面改动;及时更新密码,防止被盗用;开启两步验证,增加安全性等。
本站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本站,有问题联系侵删!
本文链接:http://www.xixizhuji.com/fuzhu/350726.html