上一篇
怎么制作一个属于自己的网页链接
制作一个属于自己的网页,无论是为了个人展示、商业推广还是学习交流,都是一项非常有趣且实用的技能,在这篇文章中,我们将详细介绍如何制作一个属于自己的网页。
我们需要了解网页的基本构成,一个典型的网页包括以下几个部分:
1. 标题:网页的标题是用户在浏览器标签页上看到的名称,通常位于页面顶部,一个好的标题应该简洁明了,能够准确反映网页的主题。
2. 导航栏:导航栏是网页的主要菜单,通常位于页面顶部或侧边,导航栏可以帮助用户快速找到网站的各个页面,提高用户体验。
3. 内容区域:内容区域是网页的主体部分,包括文字、图片、视频等元素,一个好的内容区域应该结构清晰,易于阅读。
4. 页脚:页脚通常位于页面底部,包含版权信息、联系方式等内容,页脚可以增强网页的专业感。
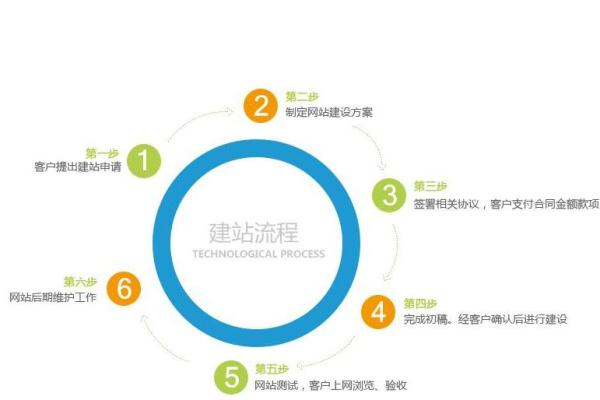
接下来,我们将介绍如何制作一个属于自己的网页,主要分为以下几个步骤:
1. 确定网页主题和目标受众:在开始制作网页之前,我们需要明确网页的主题和目标受众,这将有助于我们选择合适的设计风格和内容。
2. 设计网页布局:根据网页的主题和目标受众,设计合适的网页布局,布局应该简洁明了,易于阅读。
3. 编写HTML代码:HTML是网页的基本语言,用于描述网页的结构,我们可以使用专业的HTML编辑器(如Sublime Text、Visual Studio Code等)编写HTML代码。
4. 编写CSS样式:CSS用于描述网页的外观,如颜色、字体、布局等,我们可以将CSS代码写在HTML文件的“标签内,也可以单独编写一个CSS文件,然后在HTML文件中引用。
5. 添加内容:根据网页的主题和目标受众,添加合适的内容,内容可以包括文字、图片、视频等元素,注意保持内容的原创性和质量。
6. 测试和优化:在完成网页制作后,我们需要在不同浏览器和设备上进行测试,确保网页的兼容性和稳定性,根据测试结果对网页进行优化,提高用户体验。
7. 发布网页:我们需要将网页发布到互联网上,让其他人访问,我们可以选择免费的网站托管服务(如GitHub Pages、Netlify等),也可以购买专业的网站托管服务。
制作一个属于自己的网页并不复杂,只需要掌握基本的HTML和CSS知识,就可以轻松完成,通过不断地学习和实践,我们可以制作出更加专业和精美的网页。
相关问题与解答:
1. Q:我没有任何编程基础,可以制作网页吗?
A:当然可以,虽然编程是制作网页的基础技能,但有很多在线工具(如Wix、WordPress等)可以帮助我们轻松创建网页,无需编写任何代码。
2. Q:我应该选择哪种编程语言来制作网页?
A:目前最常用的网页编程语言是HTML和CSS,HTML用于描述网页的结构,CSS用于描述网页的外观,我们还可以使用JavaScript来实现网页的交互功能。
3. Q:我需要购买域名和网站托管服务吗?
A:购买域名和网站托管服务是可选的,域名是网站的地址,可以让其他人更容易找到我们的网站;网站托管服务则是将我们的网站部署到互联网上,让其他人可以访问,如果预算有限,我们可以选择免费的网站托管服务;如果希望获得更好的性能和稳定性,可以考虑购买专业的网站托管服务。
本站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本站,有问题联系侵删!
本文链接:http://www.xixizhuji.com/fuzhu/350607.html