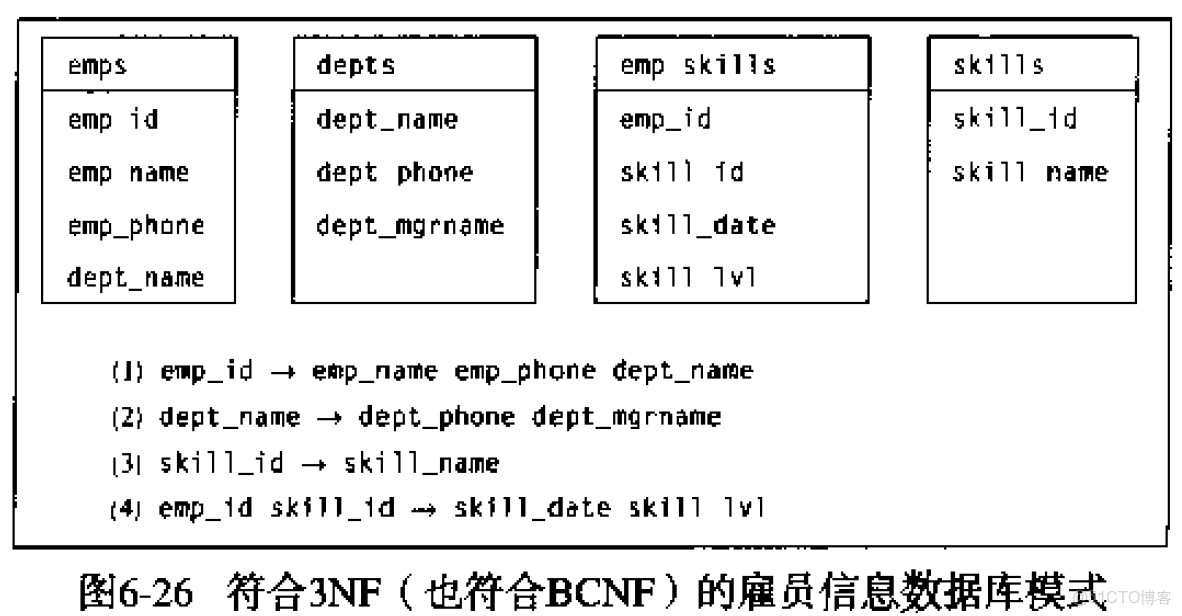
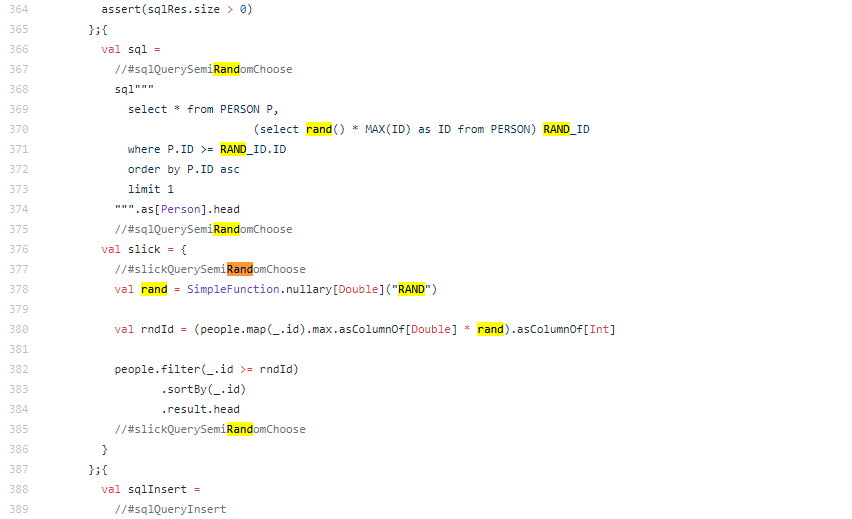
从数据库随机获取数据

ORDER BY RAND()或相应 数据库系统支持的随机函数实现。
在现代软件开发中,从数据库随机获取数据是一个常见需求,无论是为了展示随机推荐内容、进行抽样测试还是其他用途,掌握如何高效地实现这一功能都非常重要,本文将详细介绍几种常见的方法来实现从数据库中随机获取数据,并提供示例代码和相关问答FAQs。
方法一:使用SQL的ORDER BY RAND()
这是最简单直接的方法,适用于大多数关系型数据库,如MySQL、PostgreSQL等,通过ORDER BY RAND()可以随机排序结果集,然后选择其中一条记录。
示例(MySQL)
SELECT FROM your_table ORDER BY RAND() LIMIT 1;
优点:实现简单,适合小数据集。
缺点:对于大数据集,性能可能较差,因为RAND()函数会对每一行计算一个随机数,导致全表扫描。
方法二:使用数据库的随机函数结合索引
一些数据库提供了更高效的随机采样方法,比如MySQL的RAND()函数结合索引使用,或者PostgreSQL的TABLESAMPLE子句。
示例(MySQL,利用索引提高效率)
假设有一个包含大量数据的表your_table,并且id列是主键或唯一索引:
SELECT FROM your_table WHERE id >= (SELECT FLOOR(RAND() (SELECT MAX(id) FROM your_table))) ORDER BY id LIMIT 1;
这种方法首先生成一个随机的最大ID值,然后查找大于该ID的最小记录,最后按ID排序并限制结果为1条,这样可以利用索引提高查询效率。

示例(PostgreSQL,使用TABLESAMPLE)
SELECT FROM your_table TABLESAMPLE SYSTEM (1);
TABLESAMPLE SYSTEM (1)表示从表中随机抽取大约1%的行,具体比例可以根据需要调整。
方法三:应用层随机抽样
在某些情况下,可以在应用层进行随机抽样,特别是当数据库不支持高效的随机查询时,这通常涉及先获取整个数据集,然后在应用程序中进行随机选择。
示例(Python + SQLite)
import sqlite3
import random
连接到SQLite数据库
conn = sqlite3.connect('example.db')
cursor = conn.cursor()
获取所有数据
cursor.execute("SELECT FROM your_table")
rows = cursor.fetchall()
随机选择一个元素
random_row = random.choice(rows)
print(random_row)
关闭连接
conn.close() 优点:灵活性高,不受数据库限制。
缺点:对于大数据集,可能会消耗大量内存和处理时间。
方法四:使用窗口函数(适用于支持窗口函数的数据库)
一些高级数据库系统支持窗口函数,可以用来实现更复杂的随机抽样逻辑。
示例(PostgreSQL,使用窗口函数)
SELECT FROM (
SELECT , ROW_NUMBER() OVER (ORDER BY RANDOM()) AS rnum
FROM your_table
) subquery
WHERE rnum = 1; 这里使用了ROW_NUMBER()窗口函数为每行分配一个随机序号,然后选择序号为1的那一行。
相关问答FAQs
Q1: 为什么直接使用ORDER BY RAND()在大数据集上性能不佳?
A1:ORDER BY RAND()需要为每一行生成一个随机数并对其进行排序,这会导致全表扫描,尤其是当数据集很大时,计算和排序的开销会显著增加,从而影响性能。
Q2: 如何在保证随机性的同时提高查询效率?
A2: 可以通过以下方式提高效率:
利用索引:如在MySQL中使用WHERE id >= ...结合索引。
限制数据集大小:先随机选择一部分数据再进行排序,比如TABLESAMPLE。
应用层处理:如果数据库查询效率低,可以在应用层进行随机抽样,但这要求客户端有足够的内存和处理能力。