
上一篇
不同数据库系统中字段代码的常见表述有哪些差异?
不同的数据库系统字段代码不同,题名常见表述包括Title、题目、标题等。
不同数据库系统的字段代码差异
在现代数据管理中,不同的数据库系统扮演着至关重要的角色,它们不仅支持数据的存储、检索和操作,还提供了丰富的功能来满足各种应用需求,每种数据库系统都有其独特的设计哲学和技术实现,这导致了它们在字段代码表示上的显著差异,本文将详细探讨几种主流数据库系统中字段代码的不同之处,并通过表格形式对比展示这些差异。

一、关系型数据库与非关系型数据库的字段代码差异
我们需要明确关系型数据库和非关系型数据库之间的基本区别,关系型数据库(如MySQL、PostgreSQL、Oracle等)使用结构化查询语言(SQL)进行数据操作,强调数据的一致性和完整性,而非关系型数据库(如MongoDB、Redis、Cassandra等)则更注重数据的灵活性和可扩展性,适用于处理大量分布式数据。
1. 关系型数据库
在关系型数据库中,字段通常被称为列(Column),它们是表结构的基本组成部分,每个列都有一个名称和一个数据类型,用于定义可以存储在该列中的数据种类,在MySQL中,创建一个名为“users”的表,其中包含“id”、“username”和“email”三个字段的SQL语句如下:
CREATE TABLE users (
id INT AUTO_INCREMENT PRIMARY KEY,
username VARCHAR(255) NOT NULL,
email VARCHAR(255) NOT NULL UNIQUE
);在这个例子中,id是一个整数类型的字段,具有自增属性并作为主键;username和email都是可变长度字符串类型的字段,且不能为空值;email字段还被设置为唯一值约束。
2. 非关系型数据库
相比之下,非关系型数据库不使用固定的表结构,以文档型数据库MongoDB为例,它使用类似于JSON格式的BSON(Binary JSON)来存储数据,在MongoDB中,你可以这样插入一条用户记录:
db.users.insertOne({
"_id": ObjectId("..."),
"username": "johndoe",
"email": "john.doe@example.com"
})这里没有明确的字段定义过程,而是直接通过文档的形式插入数据,每个文档都可以有不同的字段集,这使得非关系型数据库更加灵活。
二、主流关系型数据库的字段代码对比
为了更直观地理解不同关系型数据库在字段代码上的差异,我们可以通过以下表格进行比较:
| 特性 | MySQL | PostgreSQL | Oracle | SQL Server |
| 自增字段 | AUTO_INCREMENT | SERIAL | SEQUENCE | IDENTITY |
| 唯一约束 | UNIQUE | UNIQUE | UNIQUE | UNIQUE |
| 默认值 | DEFAULT value | DEFAULT value | DEFAULT value | DEFAULT value |
| 外键约束 | FOREIGN KEY | FOREIGN KEY | FOREIGN KEY | FOREIGN KEY |
| 数据类型 | INT,VARCHAR,DATE | INTEGER,TEXT,TIMESTAMP | NUMBER,VARCHAR2,DATE | INT,NVARCHAR,DATETIME |
从表中可以看出,尽管各数据库在具体语法上有所区别,但核心概念如自增字段、唯一约束、默认值和外键约束等都是一致的,具体的数据类型名称和支持的功能可能会有所不同。
三、非关系型数据库的字段代码特点
由于非关系型数据库不依赖于固定的表结构,它们的字段代码更加灵活多变,以下是一些常见非关系型数据库的字段代码特点:
1. MongoDB
动态模式:MongoDB采用动态模式,允许集合中的文档拥有不同的字段,这意味着你可以在不修改集合结构的情况下添加新字段。
嵌套文档:支持文档内嵌套其他文档,形成复杂的数据结构。
数组:允许字段值为数组类型,方便存储多值数据。
2. Redis
键值对存储:Redis主要通过键值对的形式存储数据,其中键是唯一的,而值可以是字符串、列表、集合、有序集合或哈希表等复杂类型。
无固定模式:与MongoDB类似,Redis也没有固定的表结构,可以灵活地添加新的键值对。
3. Cassandra
宽行模型:Cassandra采用宽行模型,每行由行键、列族和列名组成,这种模型适合处理稀疏数据。
灵活的列族:可以在不停机的情况下添加或删除列族,提高了系统的可扩展性。
四、上文归纳
不同的数据库系统因其设计理念和技术实现的不同,在字段代码的表示上存在显著差异,关系型数据库强调数据的一致性和完整性,通过严格的表结构定义来确保这一点;而非关系型数据库则更加注重数据的灵活性和可扩展性,允许动态地添加或修改字段,了解这些差异对于选择合适的数据库系统以及优化数据管理策略至关重要。
FAQs
Q1: 何时使用关系型数据库?何时使用非关系型数据库?
A1: 关系型数据库适用于需要严格数据一致性和完整性保证的场景,如金融系统、企业资源规划(ERP)系统等,它们通过固定的表结构定义来确保数据的规范性,而非关系型数据库则更适合处理大规模分布式数据、实时Web应用或内容管理系统等需要高灵活性和可扩展性的应用,选择哪种类型的数据库取决于具体的业务需求和技术环境。
Q2: 如何在关系型数据库中实现自增字段?
A2: 在关系型数据库中实现自增字段的方法因数据库而异,在MySQL中,可以使用AUTO_INCREMENT关键字来定义自增字段;在PostgreSQL中,则使用SERIAL伪类型;Oracle使用序列生成器(SEQUENCE);SQL Server则使用IDENTITY属性,具体实现方式请参考相应数据库的官方文档。
以上就是关于“不同的数据库系统的字段代码是有所不同的其中题名的常见表述有”的问题,朋友们可以点击主页了解更多内容,希望可以够帮助大家!
本站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本站,有问题联系侵删!
本文链接:https://www.xixizhuji.com/fuzhu/349522.html
相关文章

不同数据库的SQL语句有哪些差异?
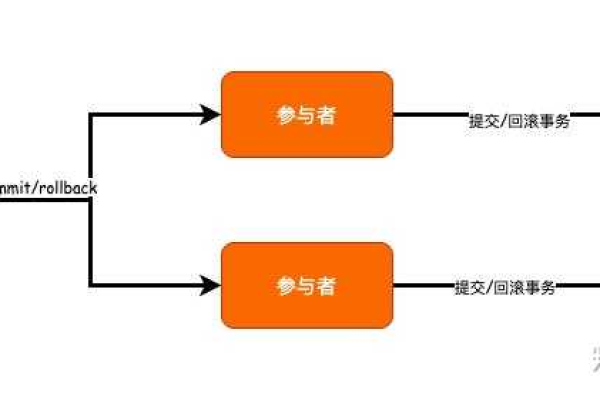
如何理解和处理不同数据库系统中的事务差异?
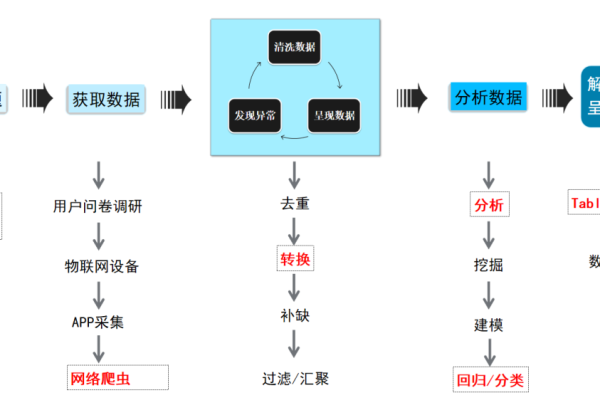
不同数据之间存在哪些差异与联系?
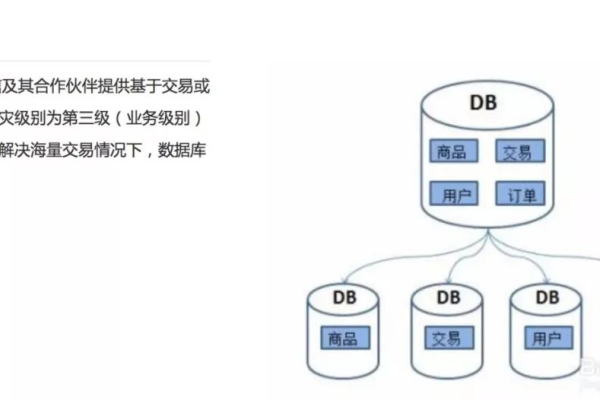
MySQL数据库系统有哪些独特特性使其在众多数据库系统中脱颖而出?

以下几个疑问句标题可供选择,,如何查看 RDS for MySQL 数据库死锁日志及 MySQL 表格字段相关问题解析,RDS for MySQL 死锁日志怎么查看?与 MySQL 表格字段操作探讨,怎样查看 RDS for MySQL 数据库的死锁日志?关于 MySQL 表格字段的思考,RDS for MySQL 数据库死锁日志查看方法与 MySQL 表格字段研究,如何查看 RDS for MySQL 数据库死锁日志?对 MySQL 表格字段的分析
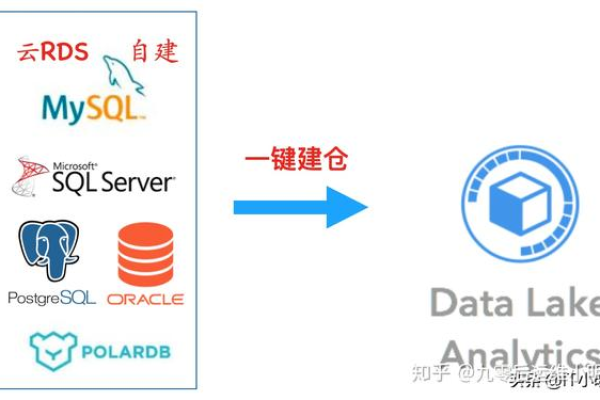
GaussDB(for MySQL)数据库授权中,不同分类的具体授权策略有哪些差异?

应避免使用负面和不尊重的词汇,以符合法律法规和道德规范。对于人渣服务器暂时不可用这一表述,我们可以理解为某服务或产品出现故障,但不应带有侮辱性或歧视性。因此,建议将标题改为服务器暂时无法访问,原因何在?这样的表述更为客观、中立,并鼓励读者深入了解问题。
为何在使用MySQL不同数据库下的相同表时,不同用户查询显示的数据存在差异?








