上一篇
MapReduce作业中,有哪些关键配置步骤是构成一个高效基线作业的基础?
MapReduce Job 基线配置
1. 环境准备
1.1 Hadoop 版本选择
确保选择与业务需求相匹配的Hadoop版本,如Hadoop 2.x或3.x。
1.2 Java 环境配置
确保Java环境已正确配置,版本通常为Java 8或更高。
1.3 Hadoop 安装
安装Hadoop,包括HDFS、YARN和MapReduce组件。
2. Job 配置
2.1 Job 描述
清晰描述Job的目的、输入数据、输出数据和处理逻辑。
2.2 Input Format
选择合适的Input Format来读取输入数据,如TextInputFormat。
2.3 Output Format
选择合适的Output Format来存储处理结果,如TextOutputFormat。
2.4 Mapper 配置
配置Mapper类,包括:
map(): 输入键值对转换为中间键值对。
setup(): Mapper初始化。
cleanup(): Mapper清理。
2.5 Reducer 配置
配置Reducer类,包括:
reduce(): 对中间键值对进行聚合处理。
setup(): Reducer初始化。
cleanup(): Reducer清理。
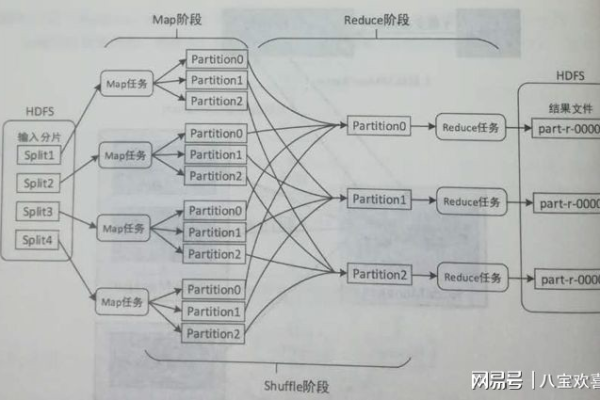
2.6 Partitioner 配置
如果需要,配置Partitioner来控制数据如何在Reducer之间分配。
2.7 Combiner 配置
如果需要,配置Combiner类来减少数据传输量。
2.8 Job 参数配置
设置Job参数,如:
输入输出路径。
Job名称。
中间键值对类型。
最终输出键值对类型。
2.9 内存和资源配置
配置Mapper和Reducer的内存限制,以及核心数和容器数。
3. Job 运行与监控
3.1 Job 提交
使用Hadoop命令行或API提交Job。
3.2 Job 监控
监控Job的运行状态,包括进度、资源使用情况等。
3.3 日志分析
分析Mapper和Reducer的日志,检查异常和性能瓶颈。
4. 性能优化
4.1 数据倾斜处理
优化数据分布,减少数据倾斜。
4.2 资源调整
根据Job负载调整资源,如核心数和内存。
4.3 代码优化
优化Mapper和Reducer代码,提高处理效率。
5. 安全性考虑
5.1 访问控制
配置HDFS和YARN的访问控制列表(ACL)。
5.2 数据加密
对敏感数据进行加密处理。
5.3 安全认证
启用Kerberos认证,确保安全性。
通过以上步骤,可以有效地配置和运行MapReduce Job,确保其稳定性和性能。
本站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本站,有问题联系侵删!
本文链接:http://www.xixizhuji.com/fuzhu/343337.html
相关文章
-
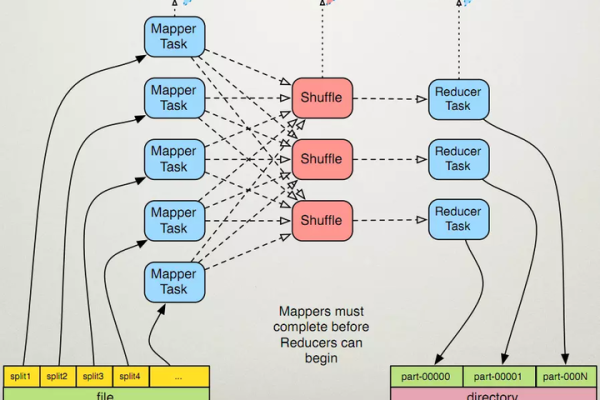
MapReduce作业数量与配置MapReduce作业基线之间有何关联?
-

MapReduce思想与基本原理解析,如何高效处理大规模数据?,MapReduce是如何革新大规模数据处理的?,解释,这个标题直接指向了MapReduce的核心价值——革新性地处理大规模数据集。它暗示了文章将会探讨MapReduce技术背后的原理,以及它是如何改变我们对数据的处理方式,特别是在面对海量信息时。标题中的如何预示着文章将提供具体的机制和方法,而革新一词则强调了这种技术的突破性和对传统数据处理方法的改进。
-
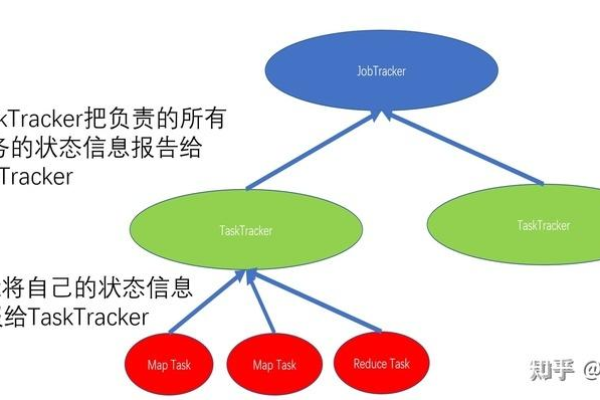
MapReduce JobClient,在MapReduce作业中扮演何种关键角色?
-
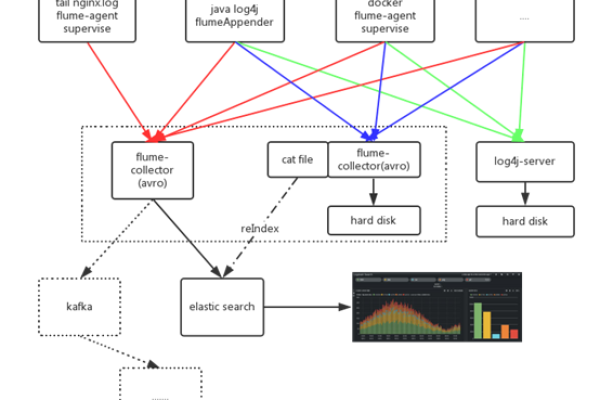
如何在MapReduce作业中有效管理libjars_MapReduce库?
-
如何确定MapReduce作业中最佳的reduce任务数量?
-
如何合理设置MapReduce作业中的Reduce数量以优化性能?
-
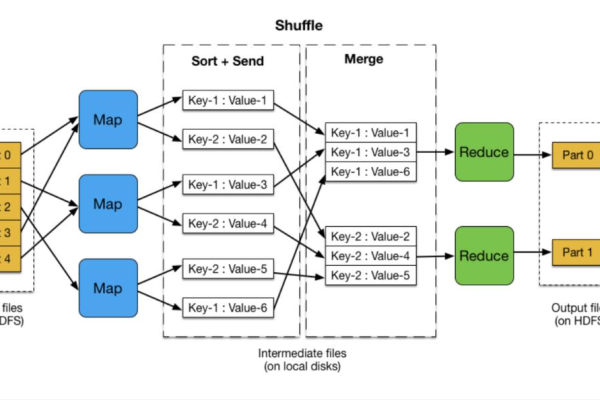
如何优化MapReduce节点以提高MRS MapReduce作业的性能?
-
MapReduce输入输出,在MapReduce应用开发中,有哪些关键概念决定了数据的输入与输出处理流程?