
上一篇
Storm怎么写一个爬虫
Storm是一个开源的分布式实时计算系统,它可以用于处理大量的数据流,在Storm中,我们可以使用Storm提供的Spouts和Bolts组件来编写一个爬虫,下面将详细介绍如何使用Storm编写一个爬虫。

我们需要了解Storm的基本概念,Storm中的组件分为两种类型:Spouts和Bolts,Spouts是数据源,它们负责产生数据流;Bolts是数据处理单元,它们负责对数据流进行处理,在Storm中,Spouts和Bolts通过消息传递的方式进行通信。
接下来,我们来看一下如何使用Storm编写一个简单的爬虫,假设我们要爬取一个网站的内容,我们可以按照以下步骤进行:
1. 定义Spout:我们需要定义一个Spout来获取网页的URL,这个Spout可以从一个预定义的URL列表中读取URL,然后将其发送到下一个Bolt进行处理。
2. 定义Bolt:接下来,我们需要定义一个Bolt来处理网页的内容,这个Bolt可以从Spout接收到URL,然后使用HTTP客户端库(如Apache HttpClient或OkHttp)向该URL发送请求,获取网页的内容。
3. 解析网页内容:获取到网页的内容后,我们需要对其进行解析,可以使用HTML解析库(如Jsoup)来解析网页的HTML结构,提取出我们需要的信息。
4. 存储数据:我们需要将解析得到的数据存储起来,可以将数据存储到数据库、文件或其他持久化存储介质中。
下面是一个简单的示例代码,演示了如何使用Storm编写一个爬虫:
// Spout类
public class URLReaderSpout extends BaseRichSpout {
private SpoutOutputCollector collector;
private List<String> urls;
public void open(Map conf, TopologyContext context, SpoutOutputCollector collector) {
this.collector = collector;
urls = new ArrayList<>();
// 从配置文件中读取URL列表
Properties prop = new Properties();
try {
prop.load(new FileInputStream("urls.properties"));
urls = Arrays.asList(prop.getProperty("urls").split(","));
} catch (IOException e) {
e.printStackTrace();
}
}
public void nextTuple() {
if (urls.isEmpty()) {
collector.emit(new Values());
return;
}
String url = urls.remove(0);
collector.emit(new Values(url));
}
}
// Bolt类
public class WebPageParserBolt extends BaseRichBolt {
private OutputCollector collector;
private String url;
private String content;
public void prepare(Map conf, TopologyContext context, OutputCollector collector) {
this.collector = collector;
}
public void execute(Tuple tuple) {
url = tuple.getStringByField("url");
// 使用HTTP客户端库获取网页内容
content = getWebPageContent(url);
// 解析网页内容并提取所需信息
parseWebPageContent(content);
}
private String getWebPageContent(String url) {
// 实现获取网页内容的逻辑,返回网页内容的字符串表示形式
return "";
}
private void parseWebPageContent(String content) {
// 实现解析网页内容的逻辑,提取所需信息并进行处理
}
}
在上面的示例代码中,我们定义了一个URLReaderSpout来读取URL列表,并将其发送到WebPageParserBolt进行处理,WebPageParserBolt使用HTTP客户端库获取网页内容,并使用HTML解析库解析网页的HTML结构,我们可以将解析得到的数据存储起来。
本站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本站,有问题联系侵删!
本文链接:http://www.xixizhuji.com/fuzhu/339719.html
相关文章
-

Storm怎么实现单词计数「storm怎么记忆」
-
storm怎么部署「storm搭建」
-
如何通过模板管理页面部署Sermant Injector以优化面部识别技术?,这个疑问句标题旨在吸引对面部识别技术和Sermant Injector部署感兴趣的读者,它提出了一个具体的操作问题,即如何使用模板管理页面来部署Sermant Injector,这是一种可能增强面部识别性能的工具。这样的标题既表明了文章的主题,也激发了读者想要了解更多具体步骤和技巧的兴趣。
-
mformat_ 似乎是一个未完成的或不完整的词汇。为了生成一个合适的疑问句标题,我需要更多的信息或上下文来理解这个短语的含义。如果您能提供更多的细节或者解释 mformat_ 代表什么,我可以帮助您创建一个相关的疑问句标题。例如,如果它是一个文件格式的缩写,那么标题可能是,,什么是MFormat文件格式?,请提供更详细的信息以便我能更准确地帮助您。
-
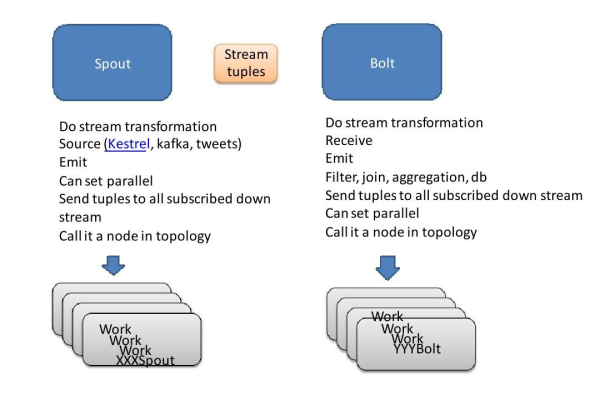
storm的MemoryMapState有什么用「memory storm」
-

Storm的Topology怎么配置「storm topology」
-
电子书drm数字加密去除,drm怎么破解(drm加密怎么解除 电子书安卓版)
-
python 爬虫 服务器_配置网站反爬虫防护规则防御爬虫攻击








