
上一篇
storm怎么记
Storm是一个开源的分布式实时计算系统,它可以处理大量的数据流并进行实时分析,在实际应用中,单词计数是一种常见的需求,可以通过Storm来实现,下面将详细介绍如何使用Storm实现单词计数。

我们需要创建一个Storm拓扑结构,Storm拓扑由一个或多个Spouts(数据源)和Bolts(数据处理单元)组成,在这个例子中,我们将使用一个简单的Spout来生成单词流,然后使用一个Bolt来计算每个单词的出现次数。
1. 创建Spout:Spout是Storm拓扑的数据源,它负责生成数据流,在这个例子中,我们可以使用随机数生成器来模拟单词流,创建一个名为WordSpout的Java类,继承自BaseRichSpout类,重写nextTuple方法,每次调用时生成一个随机单词作为输出。
import backtype.storm.spout.BaseRichSpout;
import backtype.storm.task.OutputCollector;
import backtype.storm.task.TopologyContext;
import java.util.Map;
import java.util.Random;
public class WordSpout extends BaseRichSpout {
private SpoutOutputCollector collector;
private Random random;
@Override
public void open(Map conf, TopologyContext context, SpoutOutputCollector collector) {
this.collector = collector;
this.random = new Random();
}
@Override
public void nextTuple() {
String word = "word" + random.nextInt(100);
collector.emit(new Values(word));
}
}
2. 创建Bolt:Bolt是Storm拓扑的数据处理单元,它负责对数据流进行处理,在这个例子中,我们可以使用HashMap来存储每个单词的出现次数,创建一个名为WordCounterBolt的Java类,继承自BaseRichBolt类,重写execute方法,每次接收到一个单词时,将其出现次数加一,使用collector将结果发送出去。
import backtype.storm.bolt.BaseRichBolt;
import backtype.storm.task.OutputCollector;
import backtype.storm.task.TopologyContext;
import java.util.HashMap;
import java.util.Map;
import java.util.Iterator;
import java.util.Map.Entry;
public class WordCounterBolt extends BaseRichBolt {
private OutputCollector collector;
private Map<String, Integer> wordCounts;
@Override
public void prepare(Map conf, TopologyContext context, OutputCollector collector) {
this.collector = collector;
this.wordCounts = new HashMap<>();
}
@Override
public void execute(Tuple tuple) {
String word = tuple.getStringByField("word");
int count = wordCounts.containsKey(word) ? wordCounts.get(word) + 1 : 1;
wordCounts.put(word, count);
collector.emit(new Values(word, count));
}
}
3. 配置拓扑:接下来,我们需要配置Storm拓扑,创建一个名为WordCountTopology的Java类,继承自BaseMainClass类,重写buildTopology方法,设置Spout和Bolt的配置参数,启动拓扑。
import backtype.storm.Config;
import backtype.storm.LocalCluster;
import backtype.storm.topology.TopologyBuilder;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Values;
import backtype.storm.utils.Utils;
import storm_wordcount_example.*; // 导入自定义的Spout和Bolt类
public class WordCountTopology {
public static void main(String[] args) throws Exception {
LocalCluster cluster = new LocalCluster();
cluster.submitTopology("word-count", buildTopology());
Utils.sleep(10000); // 等待10秒后关闭集群
cluster.shutdown();
}
private static TopologyBuilder buildTopology() {
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout("word-spout", new WordSpout(), 5); // 设置Spout的并发度为5
builder.setBolt("word-counter", new WordCounterBolt(), 5).shuffleGrouping("word-spout"); // 设置Bolt的并发度为5,并指定分组策略为随机分组(shuffle grouping)
return builder;
}
}
4. 运行拓扑:运行WordCountTopology类,观察单词计数的结果,在Storm UI中,可以看到每个单词的出现次数以及总计数,还可以查看拓扑的状态、任务分配等信息。
本站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本站,有问题联系侵删!
本文链接:http://www.xixizhuji.com/fuzhu/339601.html
相关文章
-

Storm怎么实现单词计数「storm怎么记忆」
-
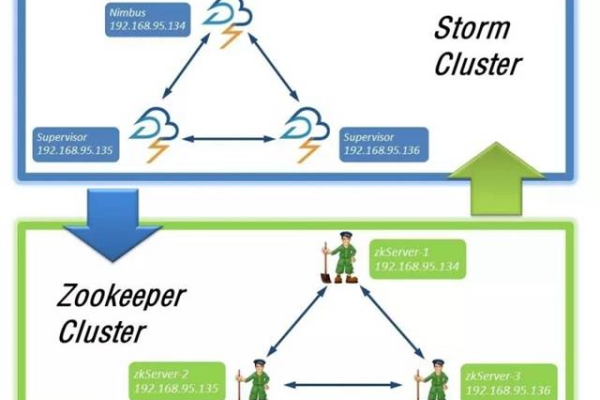
storm怎么部署「storm搭建」
-
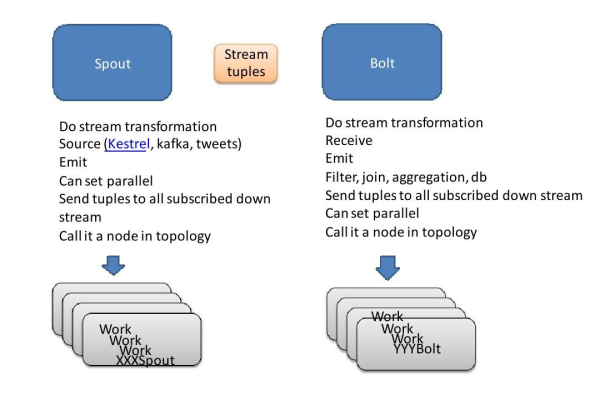
storm的MemoryMapState有什么用「memory storm」
-

Storm的Topology怎么配置「storm topology」
-
如何通过模板管理页面部署Sermant Injector以优化面部识别技术?,这个疑问句标题旨在吸引对面部识别技术和Sermant Injector部署感兴趣的读者,它提出了一个具体的操作问题,即如何使用模板管理页面来部署Sermant Injector,这是一种可能增强面部识别性能的工具。这样的标题既表明了文章的主题,也激发了读者想要了解更多具体步骤和技巧的兴趣。
-
电子书drm数字加密去除,drm怎么破解(drm加密怎么解除 电子书安卓版)
-
pycharm怎么连接mysql数据库_PyCharm ToolKit连接Notebook
-
彻底关闭stormliv.exe进程 禁止stormliv再启动








