上一篇
Storm怎么实现单词计数「storm怎么记忆」
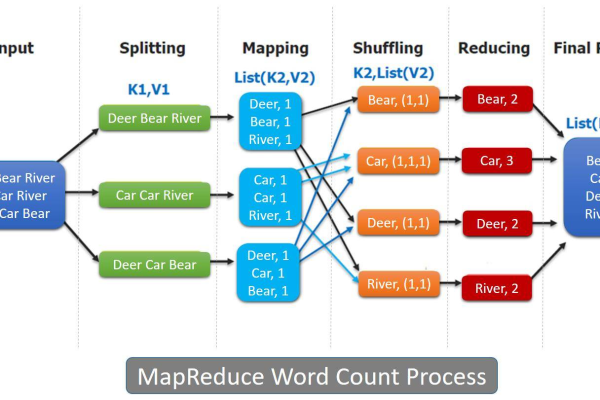
Storm是一个开源的分布式实时计算系统,它能够处理大量的数据流并进行实时分析,在实际应用中,我们经常需要对文本数据进行单词计数,以了解数据的分布情况或者进行其他相关的统计分析,下面将介绍如何使用Storm实现单词计数。
我们需要定义一个Spout来读取输入的数据流,Spout是Storm中负责生成数据流的组件,它可以从各种数据源中读取数据并发送给其他的Bolt进行处理,在本例中,我们可以使用一个简单的随机数Spout来模拟输入的数据流。
import backtype.storm.spout.SpoutOutputCollector;
import backtype.storm.task.TopologyContext;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.topology.base.BaseRichSpout;
import java.util.Random;
public class WordCountSpout extends BaseRichSpout {
private SpoutOutputCollector collector;
private Random random;
@Override
public void open(Map conf, TopologyContext context, SpoutOutputCollector collector) {
this.collector = collector;
this.random = new Random();
}
@Override
public void nextTuple() {
String word = "word" + random.nextInt(100); // 生成一个随机的单词
this.collector.emit(new Values(word)); // 发送该单词给下一个Bolt进行处理
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("word")); // 声明输出字段为"word"
}
}
接下来,我们需要定义一个Bolt来处理输入的数据流并进行单词计数,Bolt是Storm中负责处理数据流的组件,它可以对接收到的数据进行各种操作和计算,在本例中,我们可以使用一个简单的SplitBolt来将输入的单词分割成单个字符,并使用一个UpdateStateBolt来统计每个单词出现的次数。
import backtype.storm.bolt.Bolt;
import backtype.storm.bolt.OutputCollector;
import backtype.storm.bolt.projection.Projection;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Tuple;
import backtype.storm.tuple.Values;
import java.util.HashMap;
import java.util.Map;
import java.util.regex.Pattern;
public class WordCountBolt extends Bolt {
private Map<String, Integer> wordCounts; // 用于存储单词计数的Map
private Projection projection; // 用于将结果发送给下一个Bolt或输出到外部系统
private OutputCollector collector; // 用于收集结果的OutputCollector
private Pattern wordPattern; // 用于匹配单词的正则表达式
@Override
public void prepare(Map conf, TopologyContext context, OutputCollector collector) {
this.collector = collector;
this.wordCounts = new HashMap<>(); // 初始化单词计数的Map
this.projection = ProjectionFactory.getInstance().createProjection(this.collector); // 创建Projection对象
this.wordPattern = Pattern.compile("\w+"); // 编译正则表达式,用于匹配单词
}
@Override
public void execute(Tuple input) {
String sentence = input.getStringByField("sentence"); // 获取输入的字符串数据
String[] words = sentence.split("\s+"); // 将字符串分割成单词数组
for (String word : words) { // 遍历每个单词
String cleanedWord = wordPattern.matcher(word).replaceAll(""); // 清理单词,去除标点符号等非字母字符
wordCounts.put(cleanedWord, wordCounts.getOrDefault(cleanedWord, 0) + 1); // 更新单词计数
}
this.collector.ack(input); // 确认接收到该元组,触发后续Bolt的处理流程
}
}
我们需要定义一个Topology来组织和管理Spout和Bolt之间的关系,Topology是Storm中表示数据处理流程的结构,它由一系列的Spout和Bolt组成,并通过数据流连接起来,在本例中,我们可以将WordCountSpout和WordCountBolt组合在一起,形成一个单词计数的Topology。
“`java
import backtype.storm.Config;
import backtype.storm.LocalCluster;
import backtype.storm.topology.TopologyBuilder;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Values;
import org.apache.storm.Config;
import org.apache.storm.LocalCluster;
import org.apache.storm.topology.*;
import org.apache.storm.tuple.*;
import org.apache.storm.utils.*;
import org.apache.storm2jspdemo.*; // 引入自定义的WordCountBolt类和WordCountSpout类所在的包路径
本站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本站,有问题联系侵删!
本文链接:http://www.xixizhuji.com/fuzhu/339598.html