

上一篇
Oracle 11让中文充满智慧之光
Oracle 11是一款强大的数据库管理系统,支持中文字符集,让中文信息存储和处理更加高效。
Oracle 11让中文充满智慧之光
Oracle数据库是全球最流行的关系型数据库管理系统之一,它以其强大的功能、高可靠性和高性能而闻名,在Oracle 11中,中文字符集得到了更好的支持,使得中文数据能够更加高效地存储和处理,本文将详细介绍Oracle 11中中文字符集的支持技术,以及如何充分利用这些技术来提高数据库的性能和可用性。
Oracle 11中的中文字符集
Oracle 11支持多种中文字符集,包括GBK、GB2312、BIG5等,GBK字符集是最常用的一种,它包含了简体中文和繁体中文的大部分字符,在创建数据库时,可以通过指定NLS_CHARACTERSET参数来选择所需的字符集,要创建一个使用GBK字符集的数据库,可以使用以下命令:
CREATE DATABASE mydb
USER SYS IDENTIFIED BY sys_password
DEFAULT TABLESPACE users
TEMPORARY TABLESPACE temp
LOGFILE GROUP 1 ('/u01/app/oracle/oradata/mydb/redo01.log') SIZE 50M,
GROUP 2 ('/u01/app/oracle/oradata/mydb/redo02.log') SIZE 50M,
GROUP 3 ('/u01/app/oracle/oradata/mydb/redo03.log') SIZE 50M
MAXLOGFILES 5
MAXLOGMEMBERS 7
MAXLOGHISTORY 14
MAXDATAFILES 100
MAXINSTANCES 1
MAXLOGFILESPERINSTANCE 5
MAXLOGFILEBYTES 500M
MAXLOGBUFS 5
FILENAME_CONVERT = 'ALL'
CHARACTERSET AL32UTF8; Oracle 11中的中文排序规则
为了正确地比较和排序中文字符串,Oracle提供了多种中文排序规则,如ZHS16GBK_PINYIN、ZHS16CGB2312_PINYIN等,在创建表或索引时,可以通过指定NLS_SORT参数来选择所需的排序规则,要创建一个使用ZHS16GBK_PINYIN排序规则的表,可以使用以下SQL语句:
CREATE TABLE mytable (
name varchar2(50) NOT NULL,
PRIMARY KEY (name) USING NLSSORT(name COLLATE ZHS16GBK_PINYIN)
); Oracle 11中的中文全文检索
Oracle提供了全文检索功能,可以对包含中文字符的文本进行高效的搜索,在创建全文索引时,可以选择使用中文语言模型和分词器,要创建一个使用中文语言模型和分词器的全文索引,可以使用以下SQL语句:
CREATE INDEX myindex ON mytable (content) FULLTEXT CATALOG USING NLSSORT(content COLLATE ZHS16GBK_PINYIN) LANGUAGE CHINESE;
Oracle 11中的中文PL/SQL编程
在Oracle中,可以使用PL/SQL编程语言编写存储过程、触发器等程序,在编写涉及中文字符串的程序时,需要注意字符集和排序规则的选择,要编写一个处理GBK字符集的存储过程,可以使用以下代码:
DECLARE
v_name varchar2(50) := N'张三'; -GBK编码的姓名
BEGIN
-在这里编写处理姓名的代码,注意使用正确的字符集和排序规则
END; 通过以上介绍,我们可以看到Oracle 11为中文字符集提供了强大的支持,在实际应用中,可以根据需要选择合适的字符集、排序规则和全文检索配置,以提高数据库的性能和可用性,通过编写PL/SQL程序,可以实现对中文数据的高效处理,Oracle 11让中文充满智慧之光,为企业提供了强大的数据处理能力。
本站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本站,有问题联系侵删!
本文链接:https://www.xixizhuji.com/fuzhu/339296.html
相关文章
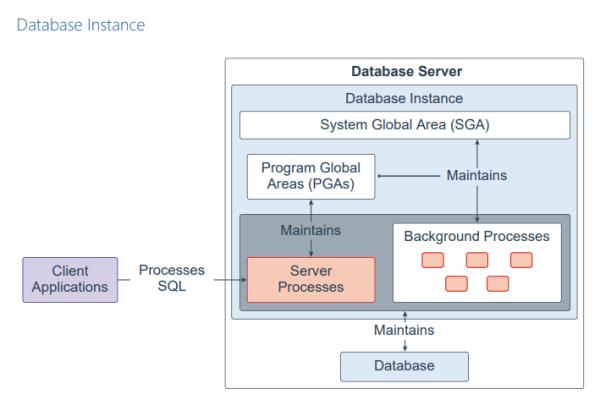
建立在Oracle Trustef Oracle数据库的基础上构建未来倚赖Oracle Trustef Oracle数据库的Oracle DB
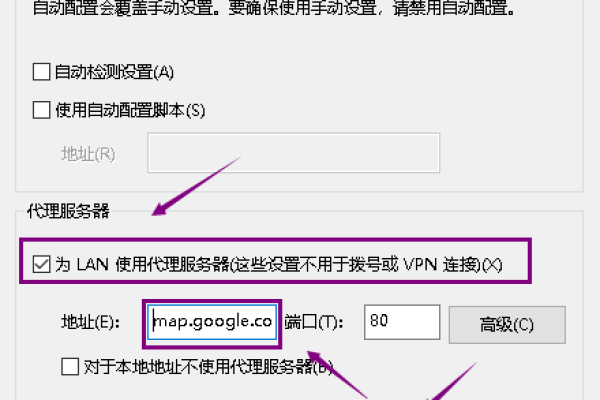
谷歌服务器如何设置中文?,如何在谷歌服务器上配置中文界面?,谷歌服务器语言设置中怎么添加中文?,谷歌服务器控制面板能切换到中文吗?,如何将谷歌服务器的语言修改为中文?,谷歌服务器管理控制台怎样选择简体中文?,在谷歌服务器设置中如何启用中文显示?,谷歌服务器支持哪些语言,如何设置为中文?,谷歌服务器后台管理可以调成中文吗?,10. 谷歌服务器有没有中文语言包或更新?,涵盖了用户可能对谷歌服务器设置中文的各种疑问和需求。

智慧Oracle10g下的智慧之路多多益善

登上 Oracle 之巅,实现全屏智慧之旅
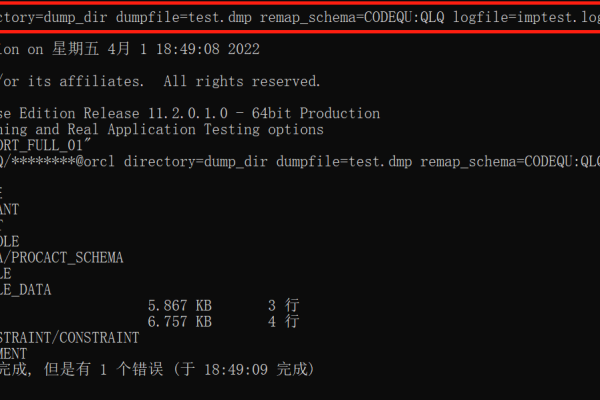
oracle数据库导出和oracle导入数据的二种方法(oracle导入导出数据)
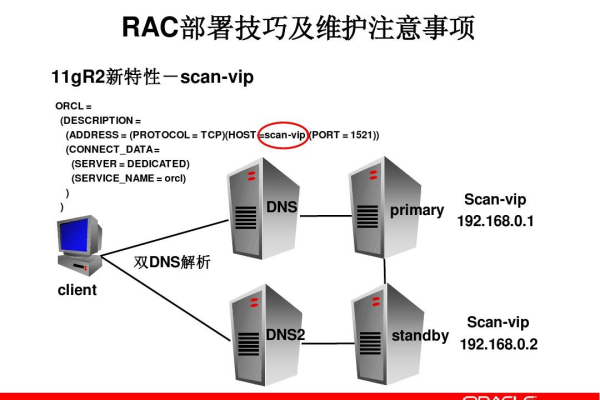
探索Oracle RAC时间服务器的使用和优势 (oracle rac时间服务器)
ORACLE ORA-01653: unable to extend table 的错误处理方案(oracle报错)
ora00904通常指的是Oracle数据库中的一个错误代码,表示在试图删除一个记录时,发现有外键依赖。因此,一个原创的疑问句标题可能是,,如何解决Oracle数据库中的ORA00904错误?








