上一篇
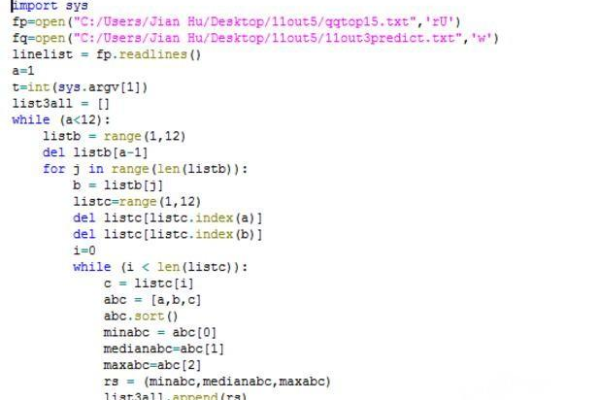
执行python.py文件
要在互联网上获取最新内容并使用Python执行Python文件,你可以按照以下步骤进行操作:

1、确定目标网站:你需要确定你想要获取最新内容的网站,这可以是新闻网站、博客、社交媒体平台等,确保你有权访问该网站并遵守其使用条款。
2、分析网站结构:在开始编写代码之前,你需要分析目标网站的结构,查看网页源代码(右键单击页面,选择“查看网页源代码”或“检查元素”),了解网站的HTML标记和数据组织方式。
3、安装所需库:为了方便地从网站上抓取数据,你可以使用一些Python库,最常用的是requests库用于发送HTTP请求,BeautifulSoup库用于解析HTML内容。
4、发送HTTP请求:使用requests库发送HTTP请求以获取目标网页的HTML内容,以下是一个简单的示例代码:
import requests url = "https://example.com" # 替换为目标网站的URL response = requests.get(url) html_content = response.text
5、解析HTML内容:使用BeautifulSoup库解析HTML内容,以便提取所需的数据,以下是一个简单的示例代码:
from bs4 import BeautifulSoup soup = BeautifulSoup(html_content, 'html.parser') 根据网站结构,使用适当的方法提取所需数据
6、提取最新内容:根据目标网站的数据组织方式,使用适当的方法提取最新内容,你可以查找具有特定类名或ID的元素,或者使用CSS选择器来定位所需数据。
7、存储数据:将提取的最新内容存储到合适的数据结构中,例如列表、字典或自定义对象。
8、执行Python文件:如果你需要执行其他Python文件来处理提取的数据,可以使用execfile()函数(仅适用于Python 2.x)或exec()函数(适用于Python 3.x),以下是一个简单的示例代码:
filename = "your_script.py" # 替换为你要执行的Python文件名 exec(open(filename).read())
9、进一步处理:根据你的需求,对提取的数据进行进一步处理,例如数据清洗、转换、存储到数据库或生成报告等。
10、自动化定时任务:如果你希望定期获取最新内容,可以使用定时任务工具,如Linux的cron或Windows的任务计划程序,来定期运行你的Python脚本。
请注意,互联网上的数据是动态变化的,因此你需要定期更新和维护你的代码,以确保能够正确获取最新内容,一些网站可能会采取反爬虫措施,因此请确保你的行为合法,并尊重网站的使用条款。
本站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本站,有问题联系侵删!
本文链接:http://www.xixizhuji.com/fuzhu/337494.html