cmd远程访问网络映射盘_网络访问

在cmd中使用网络映射盘进行远程访问是一项基本的网络管理技能,特别是在企业或教育环境中非常有用,通过映射网络驱动器,用户能够像访问本地硬盘一样轻松地访问远程服务器上的文件和文件夹,本文将详细介绍如何通过Windows的CMD命令行工具来映射、访问、和管理网络驱动器。
查看共享网络
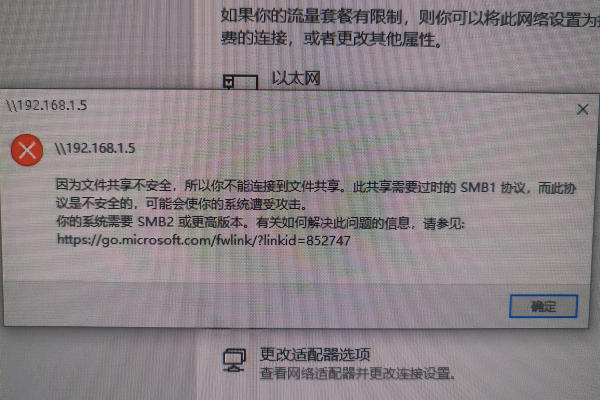
在进行网络驱动器的映射之前,首先需要确定网络上可用的共享资源,可以使用net view命令来查看网络上的共享资源,如果要查看IP地址为192.168.10.106的计算机上共享的资源,可以运行以下命令:
net view \192.168.10.106
此命令会列出该IP地址上所有可访问的共享资源。
映射网络驱动器
映射网络驱动器的基本命令是net use,其基本格式如下:
net use <驱动器字母>: \<服务器IP><共享名> [/user:<用户名> <密码>]
要将服务器192.168.56.101上的C$共享目录映射到本地的Z盘,并使用用户名“admin”及对应的密码进行连接,应执行以下命令:

net use z: \192.168.56.101c$ pass /user:admin
此后,可以直接通过访问Z盘来访问该网络共享位置的文件和文件夹。
断开网络共享连接
当不再需要访问某个网络共享时,可以手动断开其连接,使用net use命令配合/del参数可以实现这一目的,要断开前面映射的Z盘,可以执行以下命令:
net use z: /del
如果想要一次性断开所有网络共享连接,可以使用星号(*)通配符:
net use * /del
自动断开所有网络共享连接
在有些情况下,可能需要自动处理断开操作而不被提示确认,可以通过在/del参数后添加/y来实现自动确认:

net use \<IP><共享名> /del /y
或者断开所有的共享连接:
net use * /del /y
常见问题解答 FAQs
Q1: 为何我无法映射网络驱动器?
A1: 可能的原因包括:没有访问权限、共享资源不存在、网络问题或防火墙设置阻止了连接,请确保你输入正确的服务器IP地址、共享名和凭据,并且网络通畅无阻。
Q2: 如何在开机时自动映射网络驱动器?
A2: 可以通过创建一个批处理文件,并在其中包含net use命令来自动映射网络驱动器,然后将这个批处理文件放入Windows启动文件夹中,以实现开机自动运行。

下面是一个介绍,展示了使用CMD命令进行远程访问和网络映射盘(网络访问)的基本步骤和方法:
| 步骤 | 命令/操作 | 说明 |
| 查看本地共享 | net share |
查看本地计算机上设置的共享资源 |
| 查看远程共享 | net view 远程IP地址 |
查看远程计算机上可用的共享资源 |
| 映射网络驱动器(匿名访问) | net use 驱动器号: 远程IP地址共享文件夹名 |
将远程共享文件夹映射为本地驱动器,无需用户名和密码(若共享允许匿名访问) |
| 映射网络驱动器(带用户名和密码) | net use 驱动器号: 远程IP地址共享文件夹名 /user:用户名 密码 |
将远程共享文件夹映射为本地驱动器,需要输入用户名和密码 |
| 持久映射网络驱动器 | net use 驱动器号: 远程IP地址共享文件夹名 /user:用户名 密码 /persistent:yes |
映射网络驱动器并在重新启动后保持映射状态 |
| 删除网络驱动器映射 | net use 驱动器号: /delete |
删除之前创建的网络驱动器映射 |
| 删除所有网络驱动器映射 | net use /delete |
删除所有网络驱动器映射 |
| 通过命令行切换到映射的网络驱动器 | cd /d 驱动器号: |
切换到映射的网络驱动器目录下 |
| 检查网络连接 | ipconfig |
查看本地网络配置 |
| 测试与远程服务器的连接 | ping 远程IP地址 |
检测当前计算机与远程服务器的连接情况 |
| 使用特定用户测试连接 | net use 远程IP地址ipc$ "密码" /user:用户名 |
测试使用特定用户凭据连接到远程计算机 |
请注意,在使用这些命令时,确保你有足够的权限来映射网络驱动器,并且远程共享资源允许你进行这样的操作,命令中的远程IP地址、共享文件夹名、用户名和密码需要根据实际情况进行替换。