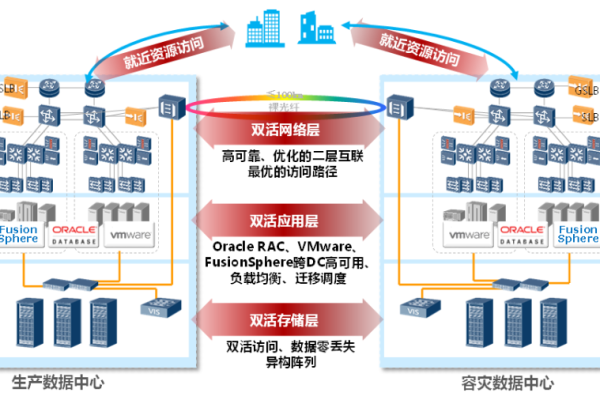
存储容灾复制对状态_复制对状态

复制对状态
在存储容灾复制中,“复制对状态”是指在存储容灾系统中,生产站点和容灾站点之间的数据复制关系及其所处状态,它通常反映了数据是否正在同步、已同步或者同步失败等信息,对于容灾恢复策略的制定和执行至关重要。
详细解析
1、复制对的概念
定义:复制对通常由一对磁盘组成,分别位于生产站点和容灾站点,这两个磁盘通过特定的数据复制技术进行数据的同步或者异步复制,以确保数据的一致性和可用性。
功能:其主要功能是确保在生产站点发生故障时,容灾站点的磁盘可以迅速接管业务,最大程度减少数据丢失和服务中断的时间。
2、复制对的状态类型
“可用”状态:当保护组处于“可用”状态时,生产站点与容灾站点的磁盘仅建立了复制对关系,但未开始数据同步,若需同步数据,需手动开启保护。
“保护中”状态:保护组处于“保护中”状态时,新添加的复制对将自动开启数据同步,此状态下,复制对的数据保持一致,适合灾难恢复演练或真实灾难恢复操作。

3、复制对状态的重要性
容灾规划:通过监控复制对的状态,企业可以有效规划灾难恢复流程,确保在不同状态下能快速、有效地应对突发事件。
数据一致性:复制对的状态直接反映了生产中心与备份中心的数据是否一致,这对于保证业务连续性和数据可靠性极为关键。
4、复制对状态管理
监控与告警:IT管理员应定期检查复制对的状态,并通过设置告警机制,当状态异常时及时进行处理,避免潜在的数据丢失风险。
状态转换:根据业务需求,管理员可以手动切换复制对的状态,如从“可用”状态转为“保护中”状态,以启动数据同步过程。

5、状态优化与策略调整
优化数据复制:通过分析复制对的状态历史,识别并优化数据复制过程中的延迟和性能瓶颈,提高系统整体的容灾能力。
策略调整:基于复制对状态的反馈,适时调整容灾策略,例如增加数据同步频率或改变同步方式,以适应业务发展和环境变化的需求。
相关FAQs
Q1: 如何检查某个复制对的当前状态?
A1: 通常可以通过存储容灾服务的管理控制台查看复制对的当前状态,登录后进入存储容灾服务页面,找到相应的保护组和复制对,其状态将被清晰列出。

Q2: 复制对状态显示为“可用”,意味着什么?需要立即采取行动吗?
A2: 状态显示为“可用”表示目前复制对已建立但没有数据同步,是否需要立即行动取决于您的容灾规划,如果希望保持数据同步,应手动开启保护。
以下是一个关于“存储容灾复制对状态”的介绍示例:
| 序号 | 复制对状态 | 描述 |
| 1 | 正常 | 复制对运行正常,主备两端数据一致,无延迟或延迟在容忍范围内。 |
| 2 | 异常 | 复制对运行异常,主备两端数据不一致,可能存在数据丢失或延迟过高等问题。 |
| 3 | 同步中 | 复制对正在进行数据同步,主备两端数据尚未完全一致。 |
| 4 | 延迟 | 复制对存在数据延迟,但仍在可接受范围内。 |
| 5 | 网络故障 | 复制对因网络故障导致无法进行数据复制。 |
| 6 | 主备切换中 | 复制对正在进行主备切换操作,此时可能存在短暂的读写受限。 |
| 7 | 初始化 | 复制对正在初始化,尚未开始数据复制。 |
| 8 | 暂停 | 复制对已暂停,不进行数据复制。 |
| 9 | 手动同步中 | 复制对正在进行手动同步操作,主备两端数据将逐步达到一致。 |
| 10 | 宕机 | 复制对所在的主机或存储设备宕机,无法进行数据复制。 |
这个介绍仅供参考,实际使用中,可以根据具体需求和场景调整复制对状态的分类和描述。