上一篇
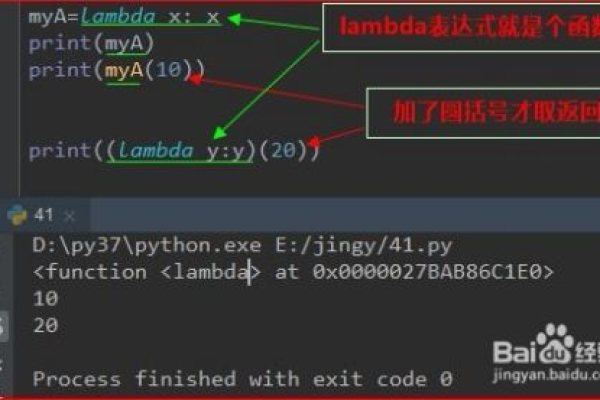
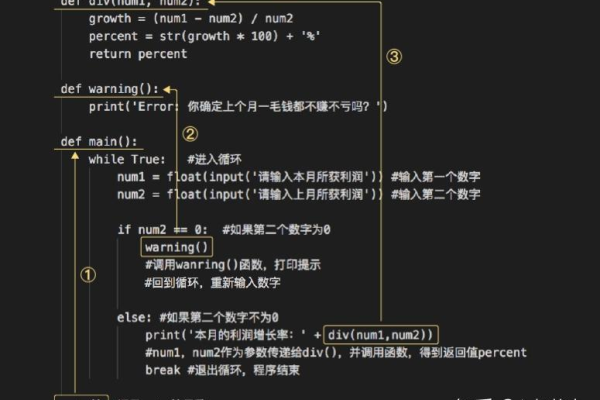
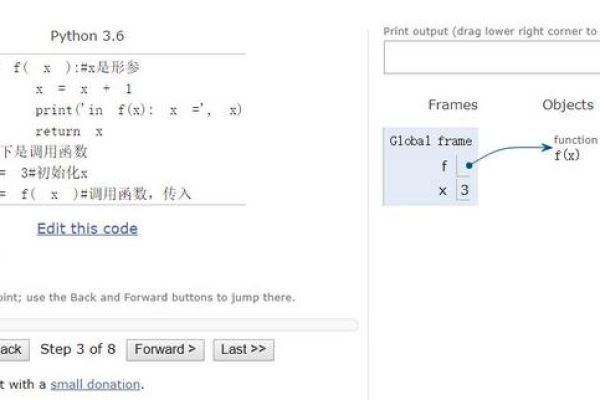
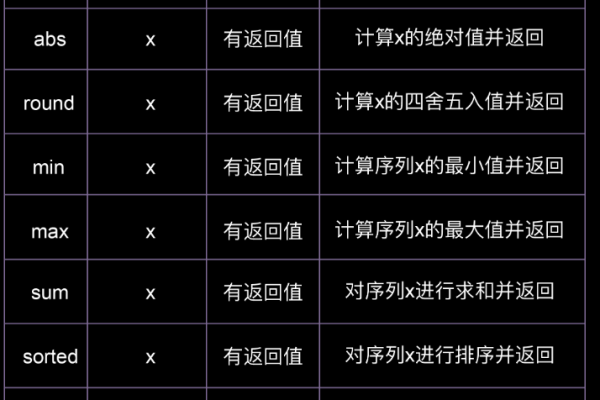
python中函数的重要作用
要在互联网上获取最新内容,可以使用Python的requests库和BeautifulSoup库,以下是一个简单的教程,教你如何使用这两个库来抓取网页内容。

1、安装所需库
确保你已经安装了requests和BeautifulSoup库,如果没有安装,可以使用以下命令进行安装:
pip install requests pip install beautifulsoup4
2、导入所需库
在Python脚本中,导入requests和BeautifulSoup库:
import requests from bs4 import BeautifulSoup
3、发送HTTP请求
使用requests库的get()方法发送HTTP请求,获取网页内容,获取新浪新闻首页的内容:
url = 'https://news.sina.com.cn/' response = requests.get(url)
4、解析HTML内容
使用BeautifulSoup库解析获取到的HTML内容,创建一个BeautifulSoup对象,然后使用该对象的方法提取所需的信息,提取所有的新闻标题:
soup = BeautifulSoup(response.text, 'html.parser')
titles = soup.find_all('a', {'target': '_blank'})
for title in titles:
print(title.text) 5、保存数据
将获取到的数据保存到文件或数据库中,以便后续分析和处理,将新闻标题保存到一个文本文件中:
with open('news_titles.txt', 'w', encoding='utf8') as f:
for title in titles:
f.write(title.text + '
') 完整代码如下:
import requests
from bs4 import BeautifulSoup
url = 'https://news.sina.com.cn/'
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
titles = soup.find_all('a', {'target': '_blank'})
with open('news_titles.txt', 'w', encoding='utf8') as f:
for title in titles:
f.write(title.text + '
') 通过以上步骤,你可以使用Python在互联网上获取最新内容,当然,这只是一个简单的示例,实际应用中可能需要根据不同的网站结构和需求进行调整,希望这个教程对你有所帮助!
本站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本站,有问题联系侵删!
本文链接:https://www.xixizhuji.com/fuzhu/337254.html