
上一篇
python 代码块注释
要在互联网上获取最新内容,可以使用Python的requests库和BeautifulSoup库来实现,以下是一个简单的示例:

1、确保已经安装了requests和BeautifulSoup库,如果没有安装,可以使用以下命令进行安装:
pip install requests pip install beautifulsoup4
2、接下来,我们编写一个简单的Python脚本来抓取网页内容并解析HTML。
import requests
from bs4 import BeautifulSoup
请求网页内容
def get_html(url):
try:
response = requests.get(url)
response.raise_for_status()
response.encoding = response.apparent_encoding
return response.text
except Exception as e:
print("获取网页内容失败:", e)
解析HTML内容
def parse_html(html):
soup = BeautifulSoup(html, 'html.parser')
# 在这里根据需要提取网页中的信息,例如提取所有的标题
titles = soup.find_all('h1')
for title in titles:
print(title.text)
主函数
def main():
url = "https://www.example.com" # 替换为你想要抓取的网页URL
html = get_html(url)
if html:
parse_html(html)
if __name__ == "__main__":
main() 在这个示例中,我们首先定义了一个get_html函数,用于发送HTTP请求并获取网页内容,我们定义了一个parse_html函数,使用BeautifulSoup库解析HTML内容,在这个例子里,我们提取了所有的标题(h1标签)。
在main函数中,我们调用这两个函数来完成网页抓取和解析的任务,你可以根据需要修改这个脚本,以适应不同的网页结构和提取需求。
注意:在使用爬虫时,请遵守网站的robots.txt规则,尊重网站所有者的权益,不要对网站造成过大的访问压力。
本站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本站,有问题联系侵删!
本文链接:https://www.xixizhuji.com/fuzhu/337227.html
相关文章

python3(python3完全兼容Python2吗)(python3.0完全兼容python2.0吗)

python 注释代码块
python批量运行cmd_python 之多主机批量执行命令(python批量执行多个py文件)

python 客户端 服务器6_Pythonbinarymemcached客户端连接Memcached(Python)
python 客户端 服务器_Pythonbinarymemcached客户端连接Memcached(Python)
客户端服务器python_Python-binary-memcached客户端连接Memcached(Python)
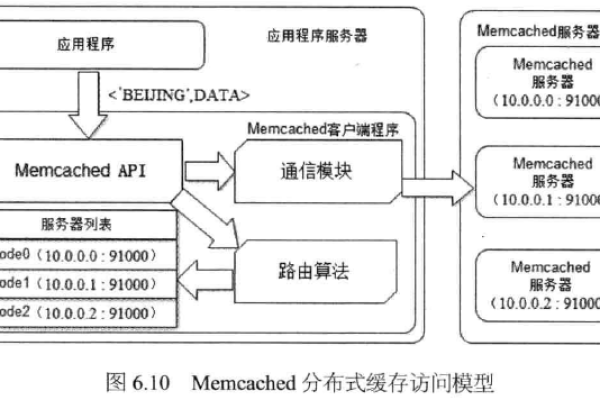
python客户端与服务器端_Python-binary-memcached客户端连接Memcached(Python)
python服务器和多个客户端_Python-binary-memcached客户端连接Memcached(Python)








