
上一篇
python 字典和列表
Python字典和列表是两种常用的数据结构,它们在处理和存储数据时非常有用,下面是一个详细的技术教学,介绍如何使用Python字典和列表来获取互联网上的最新内容。

1、使用Python字典:
字典是一种无序的数据集合,它由键值对组成,每个键都与一个值相关联,可以通过键来访问对应的值。
字典的创建:可以使用大括号 {} 或者 dict() 函数来创建一个空字典。my_dict = {} 或 my_dict = dict()。
添加键值对:可以通过赋值语句来添加键值对到字典中。my_dict['key'] = 'value'。
访问值:可以通过键来访问字典中的值。value = my_dict['key']。
遍历字典:可以使用循环来遍历字典的键值对。for key, value in my_dict.items():。
2、使用Python列表:
列表是一种有序的数据集合,它允许存储多个值,并且可以重复使用。
列表的创建:可以使用方括号 [] 或者 list() 函数来创建一个空列表。my_list = [] 或 my_list = list()。
添加元素:可以使用 append() 方法来向列表末尾添加元素。my_list.append('element')。
访问元素:可以通过索引来访问列表中的元素。element = my_list[0]。
遍历列表:可以使用循环来遍历列表中的元素。for element in my_list:。
3、获取互联网上的最新内容:
要获取互联网上的最新内容,可以使用Python的网络请求库,如requests,首先需要安装该库,可以使用以下命令进行安装:
“`python
pip install requests
“`
发送网络请求:使用requests库中的get()方法发送GET请求,并获取响应对象。response = requests.get('http://example.com')。
解析响应内容:可以使用响应对象的text属性获取响应的内容,然后使用适当的解析库(如BeautifulSoup)来解析HTML内容,提取所需的信息。
存储数据:将提取的信息存储到字典或列表中,以便后续处理和分析。
4、示例代码:
下面是一个示例代码,演示如何获取互联网上的最新内容,并将结果存储在字典和列表中:
import requests
from bs4 import BeautifulSoup
创建空字典和列表
data_dict = {}
data_list = []
发送网络请求
url = 'http://example.com'
response = requests.get(url)
html_content = response.text
解析HTML内容
soup = BeautifulSoup(html_content, 'html.parser')
articles = soup.find_all('article')
提取信息并存储到字典和列表中
for article in articles:
title = article.find('h2').text.strip()
content = article.find('p').text.strip()
# 存储到字典
data_dict[title] = content
# 存储到列表
data_list.append({'title': title, 'content': content})
打印结果
print("字典中的数据:")
print(data_dict)
print("
列表中的数据:")
print(data_list) 请注意,上述示例代码中的URL是一个占位符,您需要将其替换为您要获取最新内容的网址,根据实际情况,您可能需要调整HTML解析的代码以适应目标网页的结构。
这是一个简单的示例,展示了如何使用Python字典和列表来获取互联网上的最新内容,根据您的具体需求,您可以进一步扩展和定制代码,以满足不同的数据处理和分析要求。
本站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本站,有问题联系侵删!
本文链接:https://www.xixizhuji.com/fuzhu/337223.html
相关文章

python3(python3完全兼容Python2吗)(python3.0完全兼容python2.0吗)
python批量运行cmd_python 之多主机批量执行命令(python批量执行多个py文件)

python 客户端 服务器6_Pythonbinarymemcached客户端连接Memcached(Python)
python 客户端 服务器_Pythonbinarymemcached客户端连接Memcached(Python)
客户端服务器python_Python-binary-memcached客户端连接Memcached(Python)
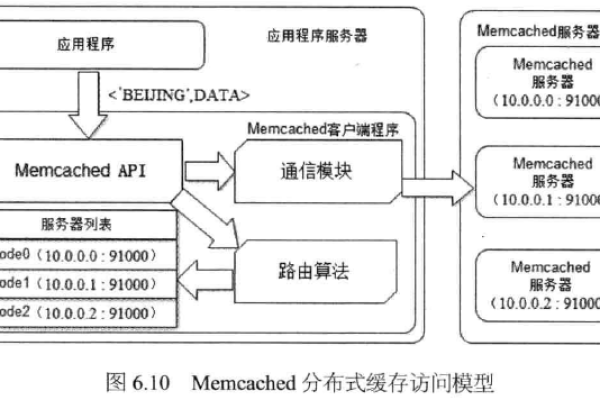
python客户端与服务器端_Python-binary-memcached客户端连接Memcached(Python)
python服务器和多个客户端_Python-binary-memcached客户端连接Memcached(Python)
python客户端服务器端_Python-binary-memcached客户端连接Memcached(Python)








