cdn安全监控cc_cc

随着互联网技术的飞速发展,内容分发网络(CDN)已经成为了网站加速和提升用户访问体验的重要工具,伴随着其广泛应用,CDN面临的安全威胁也日益增多,其中CC攻击(HTTP Flood攻击)是最为常见且具有破坏性的一种,本文将深入探讨CDN安全监控中针对CC攻击的监控机制及其重要性,并提出有效的防御措施。
CC攻击的核心在于通过大量模拟合法请求,消耗服务器资源,从而达到拒绝服务攻击的目的,这种攻击方式使得传统的防御手段难以识别和阻挡,因此对CDN的安全监控提出了更高要求。
了解CC攻击监控的数据模块是基础,根据搜索结果,CC攻击监控数据通常分为四个主要模块:请求数视图、QPS(每秒查询率)视图、攻击源排名和攻击请求TOP UA(用户代理),这些模块从不同维度展示了CC攻击的情况,为CDN运营商提供了全面的数据支持。
分析这些模块的具体作用和重要性:
1、请求数视图:该模块展示在特定时间范围内CDN接收到的总请求数,通过观察请求数量的异常波动,可以迅速发现CC攻击的迹象,这对于早期识别攻击具有重要意义。
2、QPS视图:QPS即每秒查询率,反映了CDN每秒处理的请求数量,在CC攻击发生时,QPS会急剧升高,监控此数据有助于实时了解CDN的处理压力,并及时调整防御策略。
3、攻击源排名:通过分析发起请求的IP地址,可以确定攻击流量的主要来源,这一信息对于阻断攻击源、减少攻击影响至关重要。
4、攻击请求TOP UA:用户代理(UA)数据分析显示了发起请求的设备或软件类型,识别出非正常的用户代理,有助于进一步细化防御策略,如限制来自特定UA的请求。
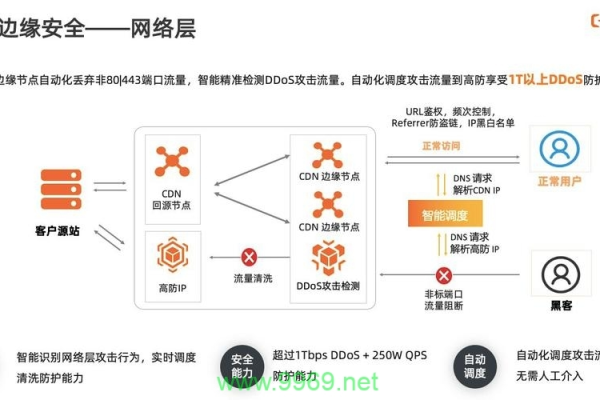
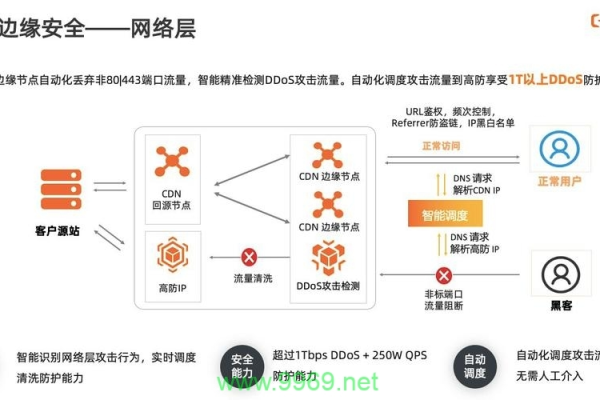
在了解了CC攻击监控的关键模块后,接下来讨论如何利用高级防御CDN来对抗CC攻击,高级防御CDN在提升网站防护能力方面扮演着重要角色,其关键职能包括流量分散和智能识别。
1、流量分散:高级防御CDN能够将流量分散到不同的服务器上,有效避免单点过载,减轻CC攻击的影响。
2、智能识别:通过算法识别异常流量模式,智能阻挡来自攻击源的请求,保护服务器免受攻击。
面对CC攻击的威胁,采取以下有效措施是保障CDN安全的关键:

定制化规则:根据业务特点设定监控阈值和响应策略,如请求限速、来源IP封锁等。
持续监控与分析:实时监控上述四个数据模块,及时发现并分析异常,快速响应。
合作防御:与CDN服务商合作,利用其专业的技术支持和防御经验,共同抵御攻击。
面对CC攻击,CDN的安全监控和防御措施是确保网站稳定运行和用户顺畅访问的关键,通过综合运用请求数视图、QPS视图、攻击源排名和攻击请求TOP UA等监控模块,结合高级防御CDN的流量分散和智能识别功能,以及定制化的防御策略,可以有效地缓解甚至阻止CC攻击带来的影响,随着网络环境的不断演变,加强CDN的安全性能,提高对CC攻击的防御能力,对于所有依赖CDN服务的网站而言都是一项长期而艰巨的任务。
相关问答FAQs
什么是CC攻击?
CC攻击,全称为Challenge Collapsar攻击,是一种利用大量模拟的合法请求来消耗目标服务器资源的网络攻击方式,这种攻击的目的是使服务器无法处理正常的请求,从而实现拒绝服务的效果。
高防CDN如何帮助抵御CC攻击?
高防CDN通过多种机制帮助抵御CC攻击,包括但不限于:

1、流量分散:将访问流量分散到多个服务器,避免单点过载。
2、智能识别与阻挡:利用算法识别出异常流量模式并自动阻挡,减少人工干预需求。
3、缓存优化:通过缓存静态内容减少对源服务器的请求,降低被攻击风险。
以下是一个基于“cdn安全监控cc_cc”主题的介绍示例,为了设计这个介绍,我假设了一些可能需要记录的信息,请注意,实际应用中,介绍的内容和格式可能需要根据具体需求进行调整。
| 序号 | 监控项目 | 监控内容 | 监控指标 | 报警阈值 | 当前状态 | 报警时间 | 处理措施 |
| 1 | 网络流量监控 | CDN网络流量 | 总流量、异常流量 | 80% | 正常 | ||
| 2 | 响应时间监控 | CDN节点响应时间 | 平均响应时间 | 200ms | 正常 | ||
| 3 | CC攻击检测 | 检测到CC攻击的次数 | 攻击次数 | 1000次/分钟 | 异常 | 20221001 10:00 | 启动防护策略,限速 |
| 4 | 节点可用性监控 | CDN节点在线状态 | 在线节点数 | 90% | 正常 | ||
| 5 | 资源占用率监控 | CDN节点资源占用率 | CPU、内存占用率 | 80% | 正常 | ||
| 6 | 状态码监控 | 返回状态码 | 2XX、4XX、5XX | 5% | 正常 | ||
| 7 | 安全防护策略监控 | 防护策略启用状态 | 策略启用数量 | 100% | 正常 | ||
| 8 | 反面请求监控 | 反面请求次数 | 反面请求次数 | 1000次/分钟 | 异常 | 20221001 11:00 | 启动拦截策略,封禁IP |
| 9 | 跨站请求伪造监控 | 检测到跨站请求伪造的次数 | CSFR攻击次数 | 100次/分钟 | 异常 | 20221001 12:00 | 启动防护策略,添加验证码 |
| 10 | SQL注入攻击监控 | 检测到SQL注入攻击的次数 | 攻击次数 | 100次/分钟 | 异常 | 20221001 13:00 | 启动防护策略,过滤特殊字符 |
这个介绍包含了以下列:
1、序号:表示监控项的编号。
2、监控项目:具体的监控内容,如网络流量、响应时间等。
3、监控内容:监控的具体指标,如CDN网络流量、节点响应时间等。

4、监控指标:用于衡量监控内容的量化指标,如总流量、平均响应时间等。
5、报警阈值:当监控指标超过该阈值时,触发报警。
6、当前状态:表示监控项目前的状态,如正常或异常。
7、报警时间:当监控项出现异常时,记录报警的时间。
8、处理措施:针对异常情况采取的处理措施,如启动防护策略、限速等。
根据实际需求,可以调整介绍的内容和格式。





热门文章
-

云服务器在搭建实时报警平台中扮演什么角色?
2024-10-04 -

MySQL存储过程的高效使用与编写指南,如何优化C语言中的MySQL存储过程?
2025-03-08 -

微信中拉黑某人后,其头像显示状态会有什么变化?
2024-11-12 -

为什么服务器在技术世界中如此受到青睐?
2024-10-08 -

QQ资料卡为何显示为空?原因何在?
2024-11-11 -

配件网站模板_网站模板设置
2024-06-23 -

如何轻松租用云服务器,关键步骤和技巧指南
2024-09-22 -

如何检查网络连接状态以确保设备已连接到互联网?
2025-03-01