
上一篇
python 字符串数组赋值
在Python中,我们可以使用多种方法从互联网获取最新内容,一种常见的方法是使用requests库来发送HTTP请求,并使用BeautifulSoup库来解析HTML响应,以下是详细的步骤和示例代码:

1、安装必要的库
确保已经安装了requests和BeautifulSoup库,如果没有安装,可以使用以下命令安装:
pip install requests pip install beautifulsoup4
2、导入库
在Python脚本中,导入所需的库:
import requests from bs4 import BeautifulSoup
3、发送HTTP请求
使用requests库发送HTTP请求,获取网页内容,我们可以获取一个新闻网站的首页内容:
url = 'https://www.example.com' response = requests.get(url)
4、解析HTML响应
使用BeautifulSoup库解析HTML响应,创建一个BeautifulSoup对象,然后使用其方法来查找和提取所需的内容,我们可以提取所有新闻标题:
soup = BeautifulSoup(response.text, 'html.parser')
news_titles = soup.find_all('h2', class_='newstitle')
5、提取文本内容
从提取到的HTML元素中提取文本内容,我们可以提取每个新闻标题的文本:
news_titles_text = [title.get_text() for title in news_titles]
6、保存到字符串数组
将提取到的文本内容保存到一个字符串数组中:
news_titles_array = news_titles_text.copy()
7、输出结果
我们可以输出提取到的新闻标题:
for title in news_titles_array:
print(title)
完整示例代码如下:
import requests
from bs4 import BeautifulSoup
url = 'https://www.example.com'
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
news_titles = soup.find_all('h2', class_='newstitle')
news_titles_text = [title.get_text() for title in news_titles]
news_titles_array = news_titles_text.copy()
for title in news_titles_array:
print(title)
请注意,这个示例仅适用于特定的网站结构,要在其他网站上执行类似的操作,需要根据目标网站的HTML结构调整BeautifulSoup的选择器。
本站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本站,有问题联系侵删!
本文链接:http://www.xixizhuji.com/fuzhu/337140.html
相关文章
-

python3(python3完全兼容Python2吗)(python3.0完全兼容python2.0吗)
-

在Python中,%s 是一个字符串格式化操作符,用于插入字符串类型的数据。当与 % 运算符一起使用时,它可以将变量的值插入到字符串的指定位置。例如,,python,name = 张三,print(我的名字是,%s % name),输出结果为,,我的名字是,张三
-
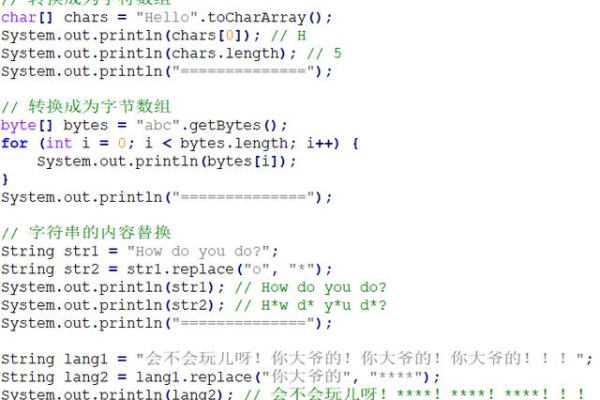
java字符串数组赋值方式
-
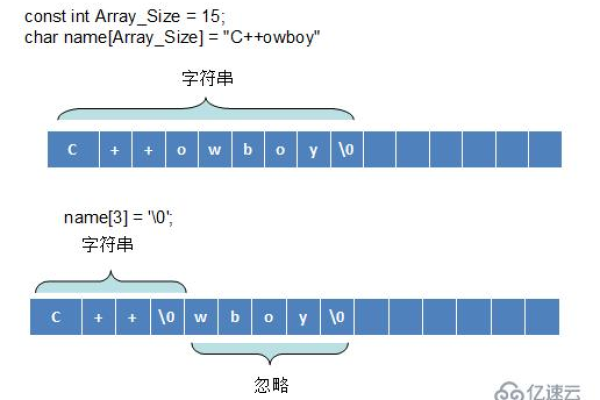
字符串数组赋值方式有哪些类型
-
存储过程报字符串数据右截位_字符串数据类型
-

python字符串数组
-
python批量运行cmd_python 之多主机批量执行命令(python批量执行多个py文件)
-
HTML 将一个字符串数组转换为锚链接,将字符串应用于< a>标签的href和文本








