dede产品展示网站模板

Dede(织梦)产品展示网站模板是一种基于织梦内容管理系统(CMS)的网页模板,专为产品展示而设计,以下是关于它的详细介绍:
一、特点
1、SEO优化:模板内置了SEO优化元素,有助于提升网站在搜索引擎中的排名,增加网站的曝光度和流量。
2、响应式设计:能够自适应电脑、手机、平板等移动设备,确保用户在不同设备上都能获得良好的浏览体验。
3、功能全面:支持定制开发,可满足不同公司对网站个性化需求的调整,如添加特定的功能模块、修改页面布局、调整颜色风格等。
4、易于操作:通常具有简单直观的操作界面,即使没有专业的技术知识,也能轻松上手进行网站的管理和内容的更新。
5、丰富的模板资源:互联网上有大量的Dede产品展示网站模板可供选择,涵盖了各种行业和风格,用户可以根据自己的喜好和需求挑选合适的模板。

二、使用方法
1、安装模板:将下载好的模板文件解压后,通过FTP工具或网站后台的文件上传功能,将模板文件夹上传到网站空间的“templets”目录下。
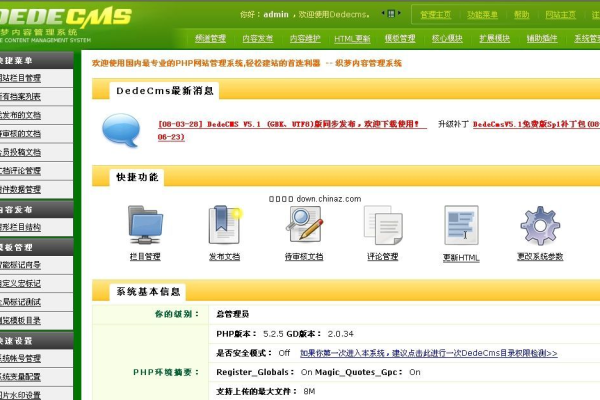
2、后台设置:登录Dede后台,进入“系统”-“系统基本参数”,设置“站点根网址”为你的域名,然后在“模板”选项中,选择默认模板为你上传的模板名称。
3、数据更新:点击“生成”-“更新主页HTML”-“更新所有”,生成新的首页和列表页等静态页面,使模板生效。
4、内容管理:登录后台后,可以方便地进行文章、图片、产品等信息的发布和管理,在添加文档时,还可以选择对应的栏目和模板,以实现不同的页面展示效果。

三、适用场景
1、企业官网:适用于各类企业的产品展示和宣传,能够有效地展示公司的服务项目、设计作品、团队介绍及客户反馈等信息,提升企业的品牌形象和知名度。
2、电商网站:可用于搭建在线商城,展示和销售产品,配合相应的支付插件和购物车功能,可以实现完整的电商购物流程。
3、产品目录网站:适合制作产品目录型网站,方便用户快速浏览和查找各类产品信息,如电子产品、机械设备、家居用品等行业的产品展示。
四、注意事项
1、安全性:要确保从正规渠道下载模板,并及时更新Dede系统和模板补丁,以防止安全破绽被利用,建议定期备份网站数据,以防数据丢失。

2、兼容性:在选择模板时,要注意其与浏览器的兼容性,确保在主流浏览器上都能正常显示,还要考虑模板与Dede系统的版本的兼容性。
3、性能优化:如果网站访问量较大,需要对模板进行性能优化,如压缩图片、精简代码、启用缓存等,以提高网站的加载速度和响应性能。
Dede产品展示网站模板凭借其多方面优势,在网站建设领域占据重要地位,无论是企业寻求线上展示窗口,还是个人打造特色产品展示平台,合理运用该模板都能高效达成目标,助力用户在网络世界中更好地呈现产品、拓展业务、吸引流量,实现自身价值的提升与传播。


热门文章
-

云服务器在搭建实时报警平台中扮演什么角色?
2024-10-04 -

MySQL存储过程的高效使用与编写指南,如何优化C语言中的MySQL存储过程?
2025-03-08 -

为什么服务器在技术世界中如此受到青睐?
2024-10-08 -

微信中拉黑某人后,其头像显示状态会有什么变化?
2024-11-12 -

QQ资料卡为何显示为空?原因何在?
2024-11-11 -

配件网站模板_网站模板设置
2024-06-23 -

如何轻松租用云服务器,关键步骤和技巧指南
2024-09-22 -

如何检查网络连接状态以确保设备已连接到互联网?
2025-03-01