查看mysql表格的数据库引擎_GaussDB(for MySQL)支持导入哪些数据库引擎的数据

GaussDB(for MySQL)支持导入多种数据库引擎的数据,以下是一些常见的数据库引擎:
1、InnoDB
2、MyISAM
3、MEMORY
4、CSV
5、ARCHIVE
6、BLACKHOLE
7、MERGE
8、FEDERATED
9、EXAMPLE
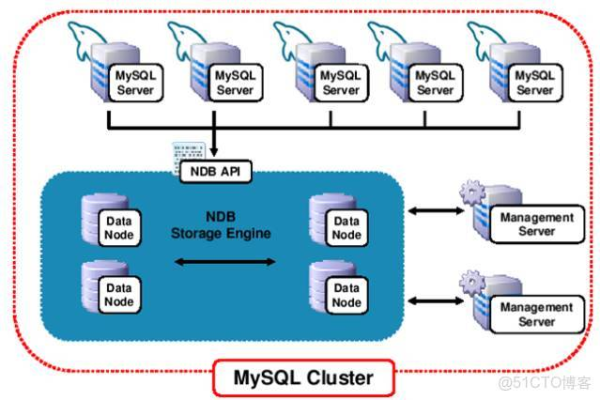
10、NDB
支持导入哪些数据库引擎的数据")
以下是这些数据库引擎的简要介绍:
1、InnoDB:支持事务处理,具有提交、回滚和崩溃恢复功能,行级锁定,支持MVCC。
2、MyISAM:不支持事务处理,表级锁定,支持全文索引。
3、MEMORY:存储在内存中的表,速度快,但数据易丢失。
4、CSV:以逗号分隔的文本文件格式存储数据,可以直接编辑数据文件。
5、ARCHIVE:用于存档和压缩数据的存储引擎,只支持INSERT和SELECT操作。
6、BLACKHOLE:不存储任何数据,用于记录其他表的操作日志。
7、MERGE:将多个MyISAM表合并为一个表,查询时会从所有表中检索数据。
支持导入哪些数据库引擎的数据")
8、FEDERATED:用于访问远程数据库表的存储引擎,基于MySQL的分布式架构。
9、EXAMPLE:示例存储引擎,用于学习如何编写自定义存储引擎。
10、NDB:用于MySQL集群的存储引擎,支持高可用性和高性能。
注意:虽然GaussDB(for MySQL)支持这些数据库引擎,但并不是所有引擎都适用于所有场景,在选择数据库引擎时,需要根据实际需求和应用场景进行选择。
下面是一个简单的介绍,列出GaussDB(for MySQL)支持的数据库引擎以及它可以导入的数据的对应关系。
| GaussDB(for MySQL) 数据库引擎 | 支持导入的数据库引擎数据 |
| InnoDB | InnoDB, MyISAM (可能需要转换) |
| GaussDB Storage Engine | InnoDB, MyISAM, CSV, ARCHIVE等 |
| MyISAM | MyISAM, CSV |
| Memory | Memory, CSV (仅限于数据结构) |
| CSV | CSV |
| Archive | Archive, CSV |
请注意,这个介绍是基于一般情况下GaussDB(for MySQL)支持的引擎和导入能力的信息整理的,实际情况可能会有所不同,导入数据时,具体支持的情况可能会根据GaussDB(for MySQL)的版本和配置而变化。
InnoDB: 是MySQL中最常用的数据库引擎,支持事务处理、行级锁定和外键等特性。
支持导入哪些数据库引擎的数据")
GaussDB Storage Engine: 华为推出的数据库存储引擎,可能具有独特的特性和优化的数据导入能力。
MyISAM: 是MySQL的另一个存储引擎,不支持事务和外键,但速度快,适用于读多写少的应用场景。
Memory: 数据存储在内存中,速度非常快,但服务器关闭后数据会丢失。
CSV: 将数据以CSV格式存储,主要用于数据导入和导出。
Archive: 用于数据归档,支持压缩,仅支持INSERT和SELECT操作。
在迁移数据时,通常需要考虑数据引擎的特性是否兼容,以及是否需要进行数据转换,在使用之前,建议查阅最新的GaussDB(for MySQL)官方文档,以获取最准确的信息和支持列表。



热门文章
-

云服务器在搭建实时报警平台中扮演什么角色?
2024-10-04 -

MySQL存储过程的高效使用与编写指南,如何优化C语言中的MySQL存储过程?
2025-03-08 -

微信中拉黑某人后,其头像显示状态会有什么变化?
2024-11-12 -

为什么服务器在技术世界中如此受到青睐?
2024-10-08 -

QQ资料卡为何显示为空?原因何在?
2024-11-11 -

配件网站模板_网站模板设置
2024-06-23 -

如何轻松租用云服务器,关键步骤和技巧指南
2024-09-22 -

如何检查网络连接状态以确保设备已连接到互联网?
2025-03-01