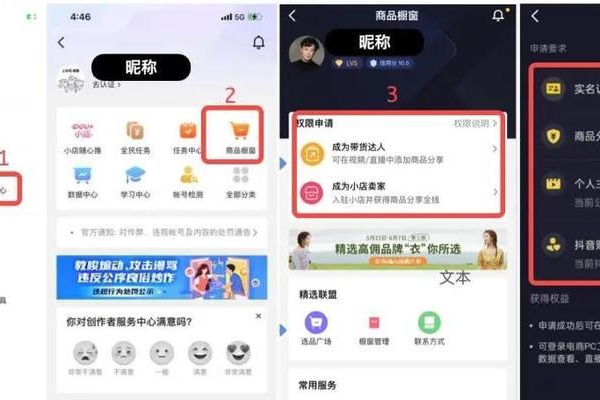
抖音开通小黄车条件

抖音开通小黄车条件如下:
1、实名认证:你需要完成实名认证,这意味着你需要提供你的身份证信息,并上传你的身份证照片。
2、年龄要求:你必须年满18岁才能申请开通小黄车。
3、信用分要求:你的信用分必须达到一定标准,这个标准可能会根据抖音的政策变化而变化,所以你需要查看最新的政策。

4、账户状态:你的账户必须是正常状态,不能有违规行为或被制裁的记录。
5、车辆要求:你需要有自己的自行车,并且车辆需要符合抖音的要求,这可能包括车辆的品牌、型号、颜色等。
6、押金:你可能需要支付一定的押金,以证明你会妥善使用小黄车。

7、保险:你可能需要购买保险,以防止在使用小黄车过程中发生意外。
8、培训:你可能需要进行一些培训,了解如何使用小黄车,以及如何遵守交通规则。
9、审核:你的申请需要通过抖音的审核,如果你满足所有的条件,那么你的申请通常会被批准。

10、合同:你需要同意并签署一份合同,确认你理解并同意所有的条款和条件。
以上就是开通抖音小黄车的条件,请注意,这些条件可能会根据抖音的政策变化而变化,所以你需要查看最新的政策。